Nové mluvené korpusy češtiny:
ORTOFON a DIALEKT
Zuzana Komrsková, Marie Kopřivová, David Lukeš, Petra Poukarová, Hana Goláňová
Bratislava, konference SLOVKO, 27. října 2017
Ukázky
Krátké seznámení na začátek
Slajdy jsou k dispozici na adrese https://trnka.korpus.cz/~lukes/slides/slovko2017.
Úvod
Korpusy mluvené češtiny v ČNK
Obecné
| korpus | # slov | roky sběru |
|---|---|---|
| ORTOFON | 1 mil. | 2012–2017 |
| ORAL | 5,4 mil. | 2002–2011 |
| ↳ ORAL2013 | 2,8 mil. | 2008–2011 |
| ↳ ORAL2008 | 1 mil. | 2002–2007 |
| ↳ ORAL2006 | 1 mil. | 2002–2006 |
| BMK | 490 tis. | 1994–1999 |
| PMK | 675 tis. | 1988–1996 |
Specializované
| korpus | # slov | roky sběru |
|---|---|---|
| DIALEKT | 100 tis. | 1957–2015 |
| LINDSEI_CZ | 120 tis. | 2012–2015 |
| SCHOLA2010 | 790 tis. | 2005–2008 |
ORAL = ORAL2006 + ORAL2008 + ORAL2013 + dříve nezveřejněná data
ORTOFON
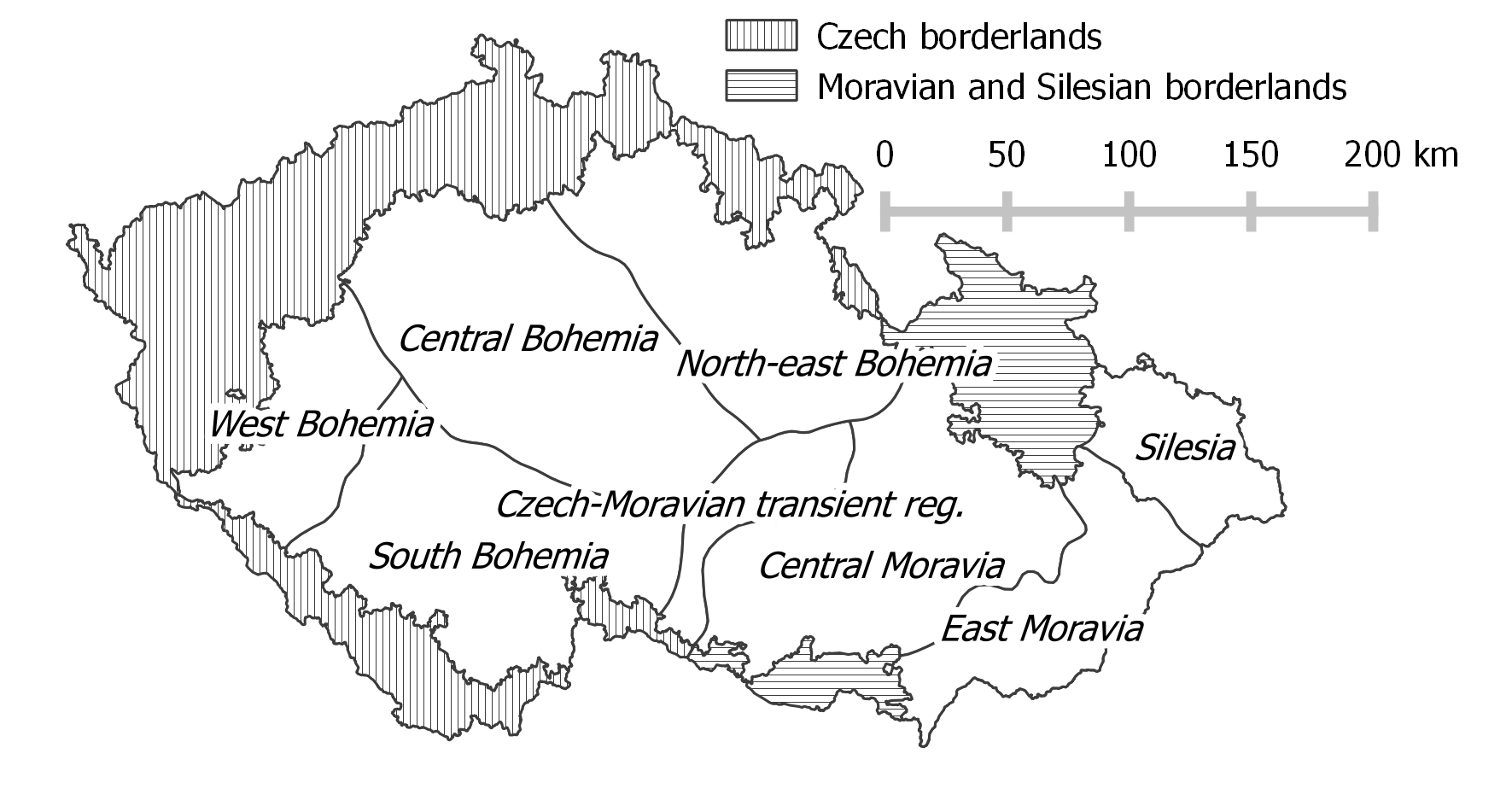
Geografické rozložení dat
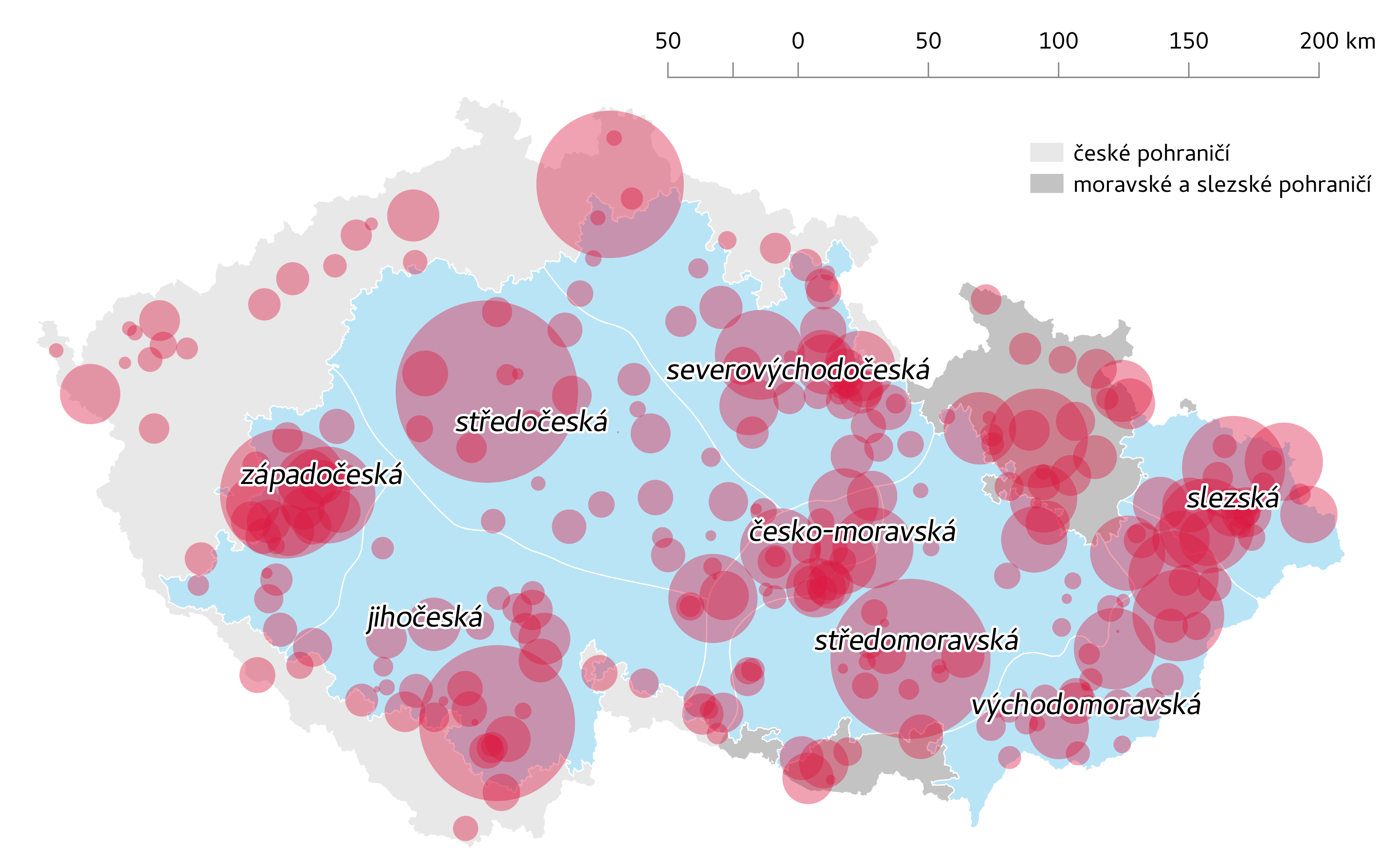
Kontextová metadata
Na úrovni dokumentů (strukturní jednotky <doc/>).
doc.situation: 12 předdefinovaných typů situacídoc.year,doc.month,doc.location: čas a místo nahrávkydoc.relationship: vztahy mezi mluvčími v nahrávcedoc.genders: zastoupení pohlaví mezi mluvčími v nahrávcedoc.generations: počet generací zastoupených v nahrávce- … a další.
Demografická metadata
Na úrovni mluvčích (strukturní jednotky <sp/>).
sp.gender: pohlavísp.age: věksp.edu_level,sp.edu_field: úroveň a oblast nejvyššího dosaženého vzdělánísp.occupation: zaměstnánísp.{reg,loc,locsize}_{childhood,longest,current}: {nářeční oblast, místo, velikost místa} pobytu {v dětství, nejdelšího, současného}sp.proportion: podíl replik mluvčího na celkové konverzaci- … a další.
Anotace v ELANu
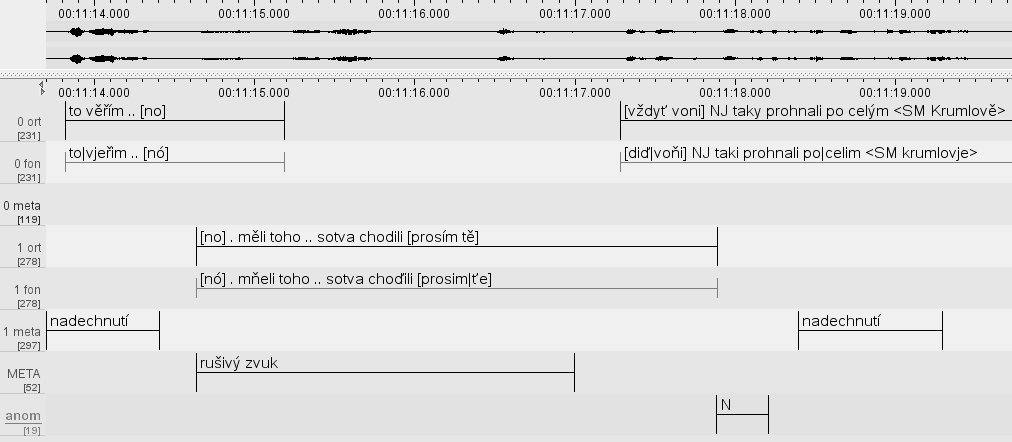
Obecné charakteristiky anotace
Hlavní inovace oproti sérii korpusů ORAL: víceúrovňový přepis. Historie nástrojů pro přepis:
- textový editor (ORAL2006, ORAL2008)
- Transcriber (ORAL2013 + dodatky)
- ELAN (ORTOFON)
Segmenty o max. délce 25 tokenů (usnadňuje revizi a práci s korpusem).
Překryvy značené pomocí [...] v rámci segmentů.
Struktura vrstev
Transkripční vrstvy:
- vrstva ort (každý mluvčí)
- na ni napojená vrstva fon
Anotační vrstvy:
- vrstva meta (každý mluvčí)
- sdílená vrstva META
- sdílená vrstva anom
Vrstva ort
První fáze přepisu, spolu s anotačními vrstvami.
Kompromis mezi dvěma protichůdnými požadavky:
- držet se blízko standardního zápisu jazyka
- zachovat lexikální a morfologická specifika
Prozodicky motivovaná interpunkce:
.= prozodický předěl (případně s pauzou do 120 ms)..= pauza 120 ms – 2 s- pauzy nad 2 s = samostatné segmenty ve stopě
meta
Průvodní jevy: např. <SM nápady> = se smíchem
V transkripci zachováváme
- protetické v- a h-
vokno,hulica
- nářeční změny v kořenových vokálech
mlýn–mlejn–mlén,louka–lúka–lóka
- nářeční koncovky při skloňování a časování
s malejma nákladama,mají–maj–majú–majó
- zkrácené podoby l-ových participií
moh,spad,řek
V transkripci sjednocujeme…
… většinu foneticky motivované variability (× korpusy řady ORAL)
- nestandardní vokalická délka
mam > mám
- zjednodušené konsonantické shluky
dycky > vždycky,šesnáz > šestnáct
- další formální redukce (vynechání slabik aj.)
prže > protože
Vrstva fon
Druhá fáze přepisu (až po kontrole vrstvy ort).
- zjednodušená fonetická transkripce
- s maximálním využitím grafémů české abecedy
- bez fonetické diakritiky
- značení hranic přízvukových taktů
- alignace s vrstvou ort: tokeny si odpovídají \(1:1\)
Vyvažování
Kategorie pro vyvažování:
- pohlaví: muži × ženy
- věk: do 35 let × nad 35 let
- vzdělání: ZŠ + SŠ × VŠ
- nářeční oblast původu: 10 oblastí
Výsledný počet kategorií: \(2 \times 2 \times 2 \times 2 \times 10 = 80\)
Ideál: rovnoměrné zastoupení těchto 80 kategorií, alespoň 5 mluvčích na kategorii.
→ Cílový počet slov na kategorii: \(\frac{1\ 000\ 000}{80} = 12\ 500\)
Grafické znázornění v rámci jedné oblasti
Hrubá síla?
- z množiny sond o velikosti \(N\) lze vybrat \(2^N\) podmnožin, tj. potenciálních kandidátů na složení korpusu
- v našem případě \(N \approx 600\) → řádově \(2^{600}\) kandidátů
- atomů ve vesmíru je řádově \(2^{115}\)
Heuristický algoritmus
- vybrat první sondu do korpusu náhodně
- další sondy přidávat tak, aby se vždy ve vyvažovacích metadatech co nejvíce lišily od průběžné podoby korpusu, dokud korpus nedosáhne cílové velikosti (1M)
- opakováním kroků 1–2 vytvořit co nejvíce (tisíce) kandidátů na finální korpus
- definovat cílovou funkci, která usouvztažní jednotlivé požadavky na složení korpusu a kvantifikuje závažnost jejich porušení
- pomocí cílové funkce z bodu 4 vybrat ze seznamu z bodu 3 nejlepší (nejméně špatné) řešení
Exaktní řešení?
S použitím známých optimalizačních algoritmů (lineární programování aj.)?
Ale:
- promluvy mluvčích nevybíráme samostatně, ale v rámci sond
- výsledný korpus \(\approx\) zdrojová data
- “nedostatkoví” mluvčí často spojeni s mluvčími “přebytkovými”
- optimální řešení úlohy neexistuje, jen řešení více či méně “špatná”
DIALEKT
Metadata
Víc zaměřená na specifikaci nářečního původu mluvčího. Tradiční tříúrovňové dělení:
- nářeční oblast
- nářeční typ
- nářeční úsek
Cíleno na starší mluvčí (nad 60 let), bez VŠ vzdělání, dlouhodobě pobývající ve stejné venkovské lokalitě.
Nářeční oblasti
Anotace v ELANu
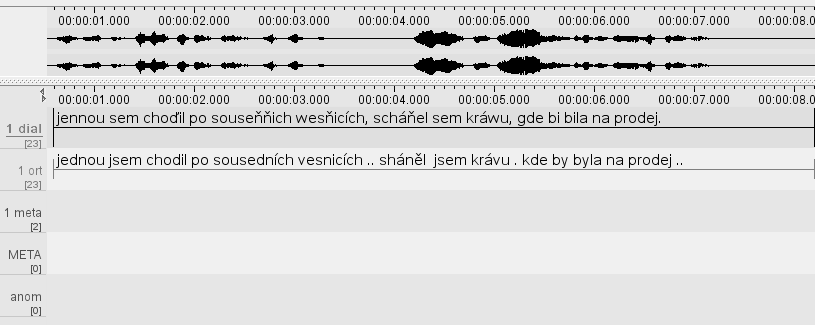
Struktura vrstev
Transkripční vrstvy:
- vrstva dial (každý mluvčí) (× ORTOFON)
- na ni napojená vrstva ort
Anotační vrstvy:
- vrstva meta (každý mluvčí)
- sdílená vrstva META
- sdílená vrstav anom
Vrstva dial
Vychází ze standardních Pravidel pro vědecký přepis dialektologických zápisů českých a slovenských.
Užívá specifické symboly pro zachycení nářečních hlásek, např.: vǝrch, býł, won, řezňičił.
Hranice slov a interpunkce naopak odpovídají psanému jazyku.
Vrstva ort
Větší lexikální, morfologická a fonologická variabilita si někdy vyžaduje agresivnější standardizaci než u ORTOFONu.
Hlavní rozdíly dial > ort:
- na rozdíl od protetického v- není zachováno protetické h-
herteple > erteple
- vokalické změny v kořeni
kúřilo sa > kouřilo se,sejtko > sítko
- regionálně podmíněné konsonantické změny
svareb > svateb,skoval > schoval,kameň > kámen
Lemmatizace a značkování
Mluvený jazyk: substandardní, útržkovitý, kontextově vázaný, multilineární → problémy pro automatické nástroje

Substandardnost
Dvě komplementární linie řešení:
- co největší standardizace přepisu, aniž by utrpěl dojem mluvenosti
- úprava nástrojů, aby počítaly se substandardními jevy
- manuální / (polo)automatické úpravy morfologického slovníku
A co další problémy?
Útržkovitost, vázanost na kontext, multilinearita…
Jejich řešení by vyžadovalo změny v:
- technologických postupech využívaných pro automatické značkování
- lingvistickém popisu mluvené řeči
Díky za pozornost!
Díky za pozornost!
Tento příspěvek vznikl při realizaci projektu Český národní korpus (LM2015044) financovaného Ministerstvem školství, mládeže a tělovýchovy v rámci aktivity Projekty velkých infrastruktur pro VaVaI.
Slajdy jsou k dispozici na adrese https://trnka.korpus.cz/~lukes/slides/slovko2017.