Multi-dimensional analysis of Czech
Václav Cvrček
Zuzana Komrsková
David Lukeš
Petra Poukarová
Anna Řehořková
Adrian Jan Zasina
24th September 2018
Dim 1: dynamic (+) × static (-)
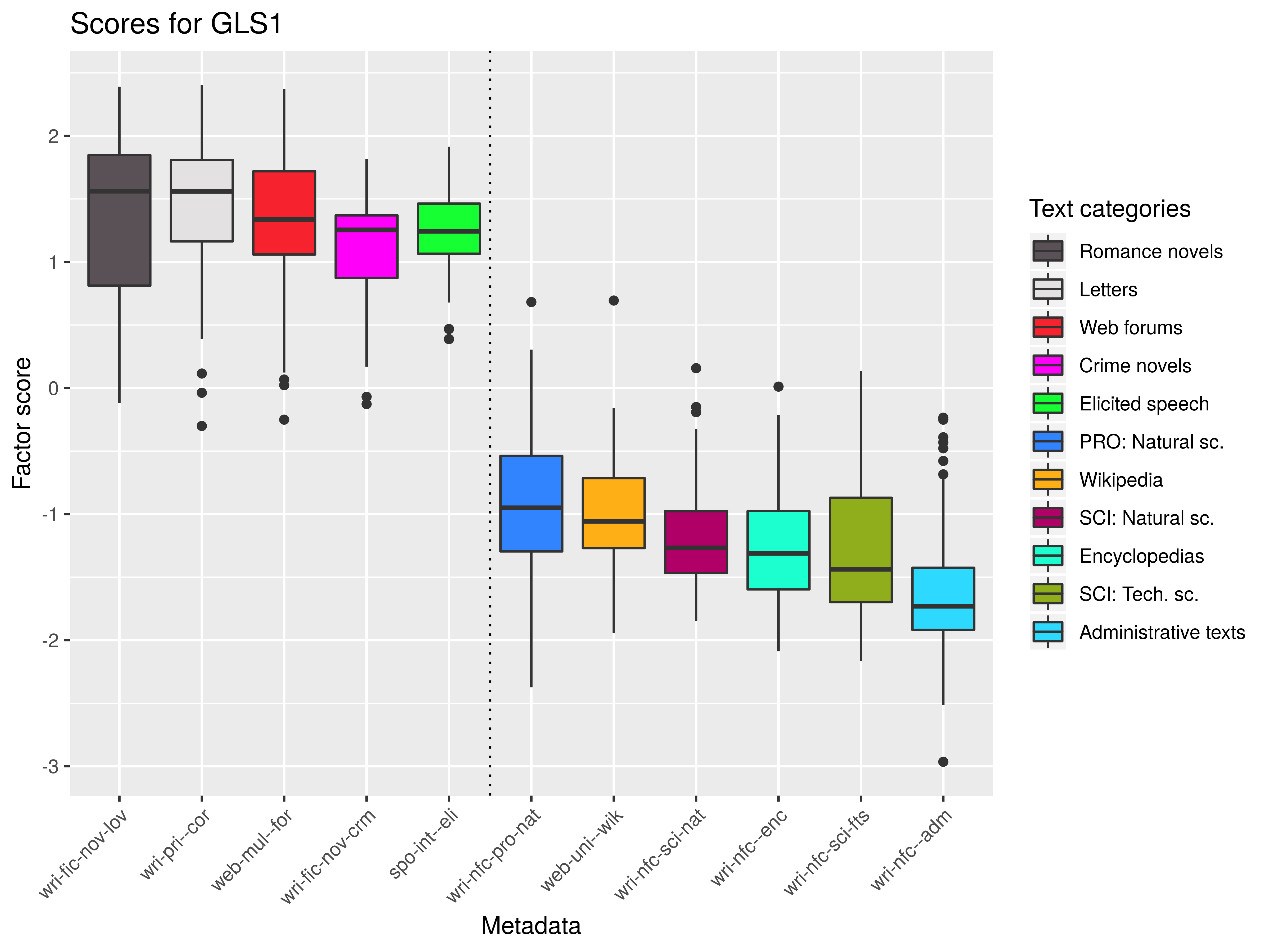
Dim 2: spontaneous (+) × prepared (-)
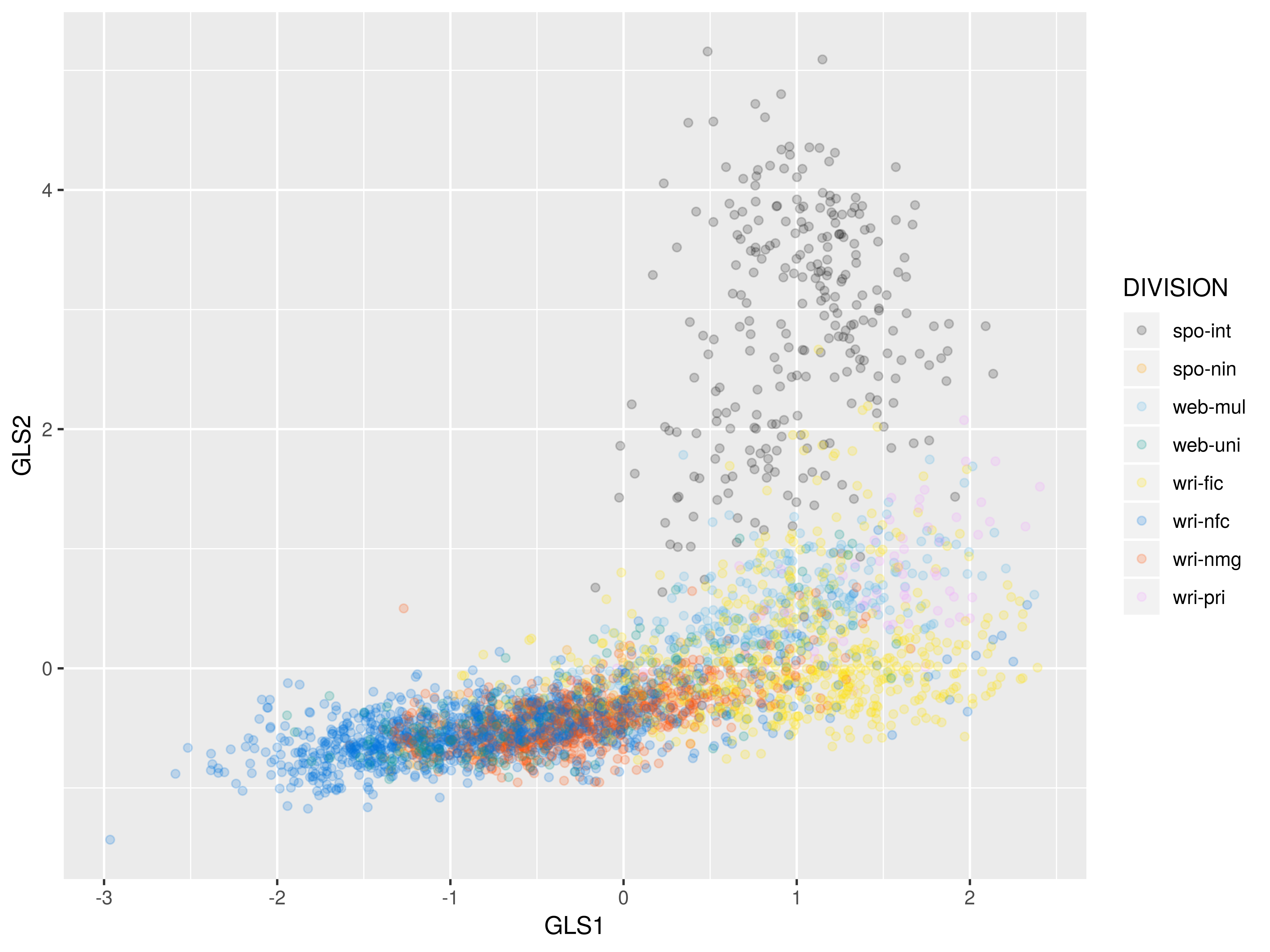
2D-plot: dim 1 and dim 2
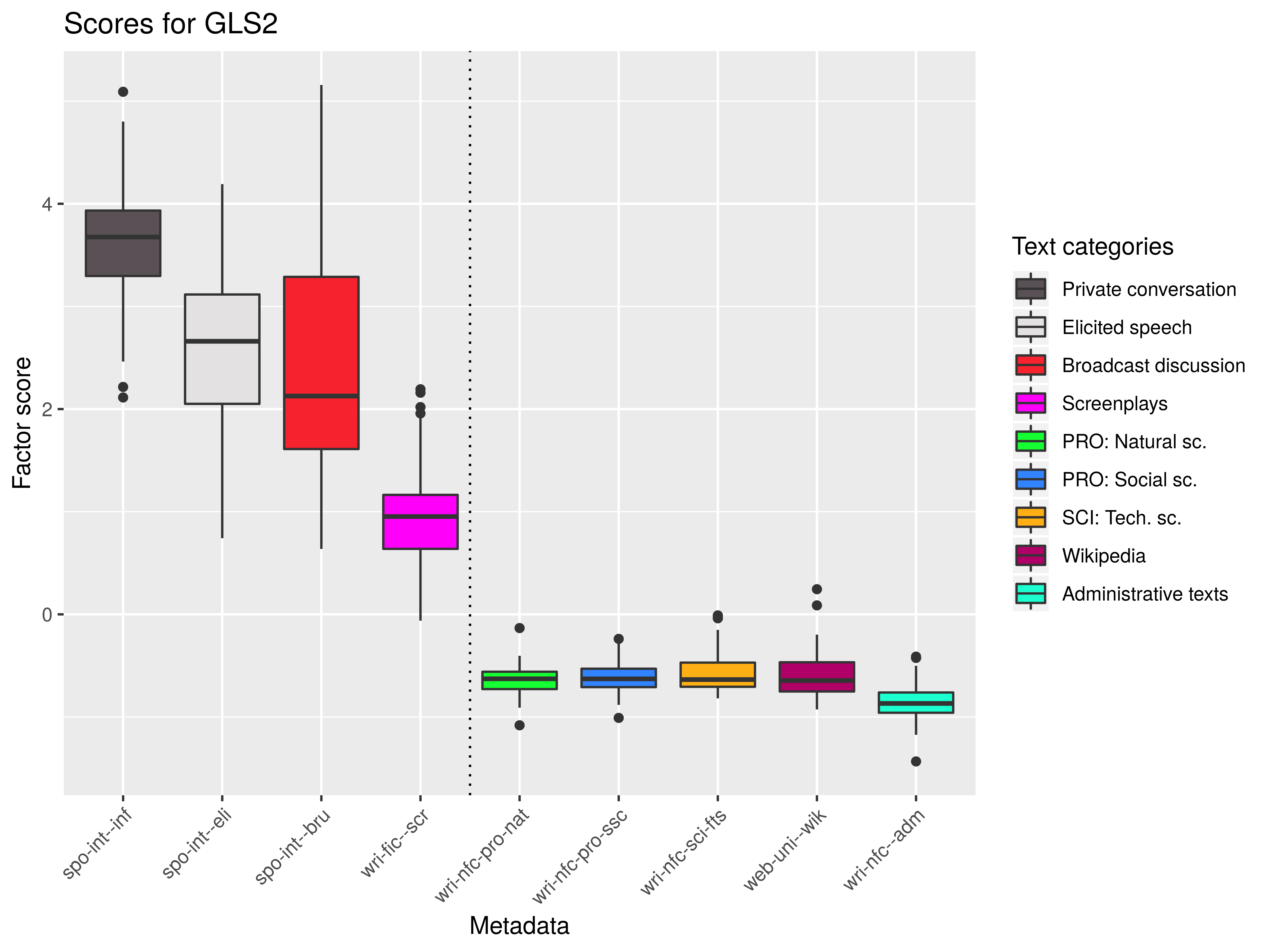
Dim 5: higher (+) × lower (-) amount of addressee coding
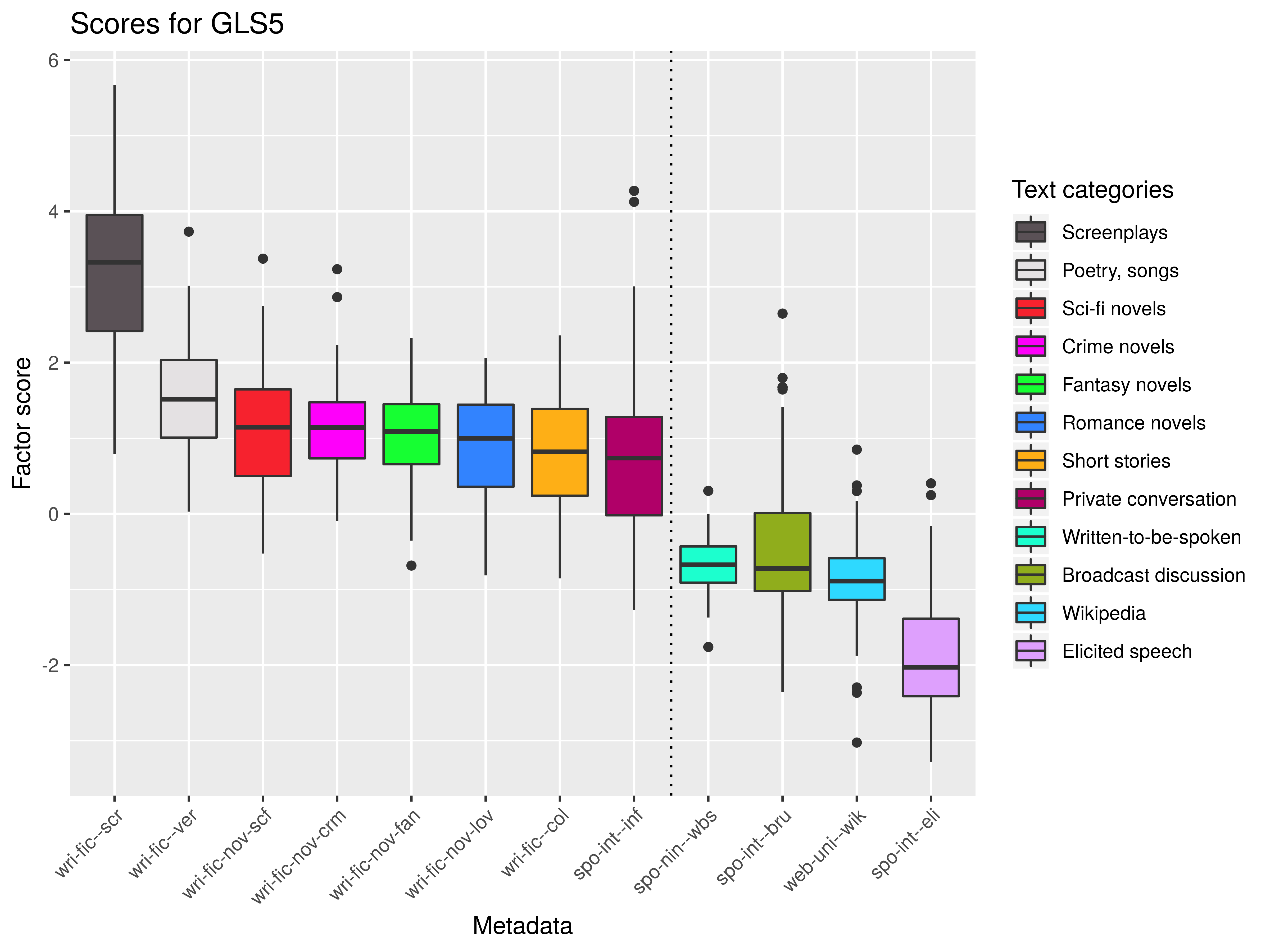
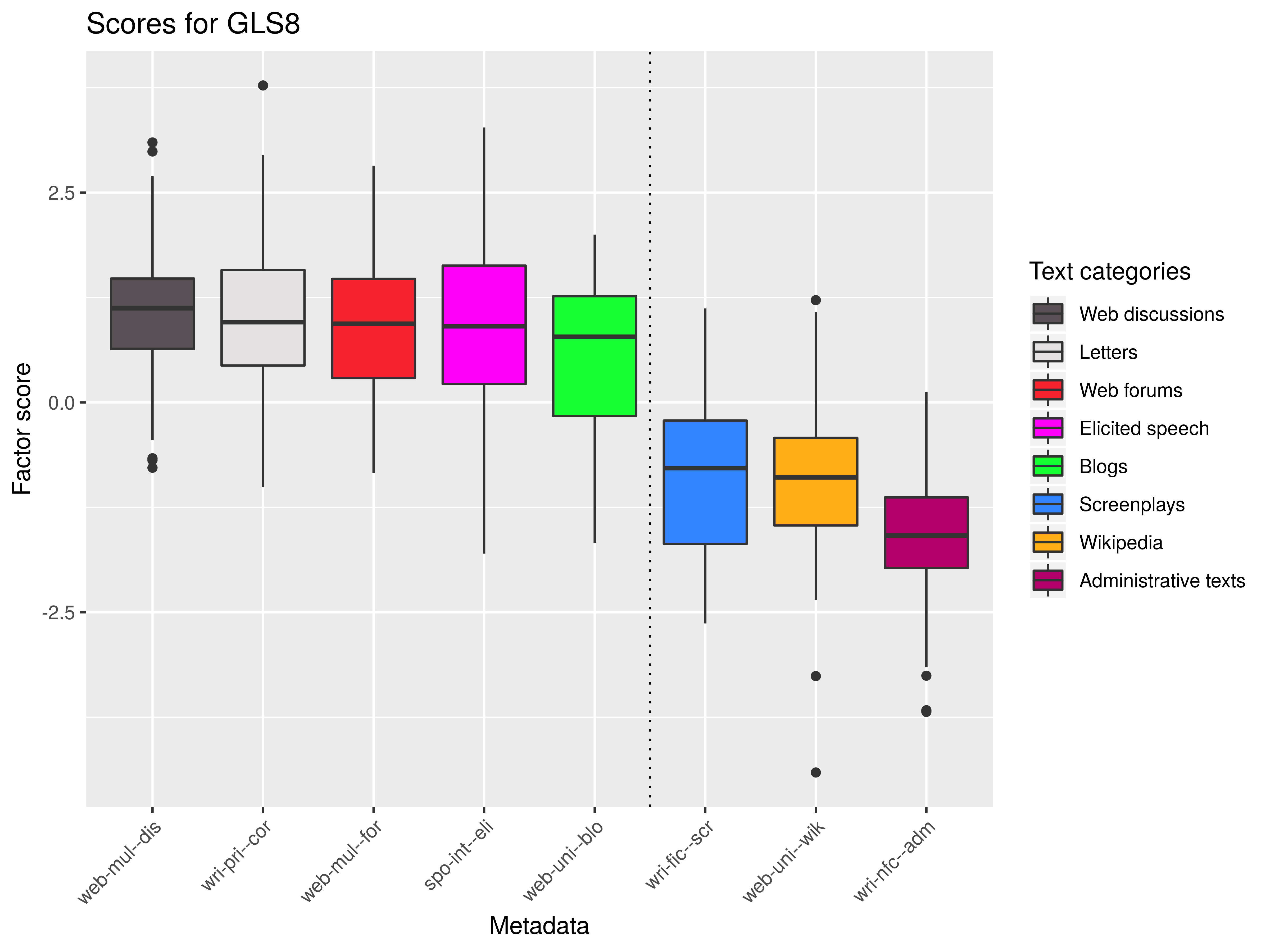
Dim 8: attitudinal (+) × factual (-)
Acknowledgments
This research was supported by the ERDF project Language Variation in the CNC no. CZ.02.1.01/0.0/0.0/16_013/0001758.
It builds upon work made possible by the Czech National Corpus project (LM2015044) funded by the Ministry of Education, Youth and Sports of the Czech Republic within the framework of Large Research, Development and Innovation Infrastructures.
