Fonetický přepis
v korpusu ORTOFON
Úvod (I)
- jak takový přepis vrstvy fon vypadá
- kdo na něm pracuje: většinou specializovaní spolupracovníci
{kind=link}
Úvod (II)
Kdybychom měli pravidla vymyslet...
- co víme o fonetickém přepisu?
- co víme o našem materiálu?
- situace
- způsob nahrávání
co víme o projektu ORTOFON?
- kdo sbírá data?
- kdo je přepisuje?
→ Jak bychom tedy mohli postupovat při vytváření transkripčních pravidel pro fonetický přepis?
Postup
- Schválení vrstvy ort v databázi a “překlopení” přepisu na vrstvu fon.
- provedou se některé základní záměny znaků, které se na vrstvě fon (skoro) nepoužívají, např.
měkký→mňekí
- provedou se některé základní záměny znaků, které se na vrstvě fon (skoro) nepoužívají, např.
- Přepis vrstvy fon v Transcription Mode v ELANu.
- možnost rozkliknout si daný úsek detailněji i v Praatu
- Kontrola alignace vrstev ort a fon pomocí programu TransVer
- Vložení do databáze, kontrola přepisu (automatická i lidská), dodatečné opravy.
Co a jak zachycujeme? (I)
- dokument Instrukce k přepisu stopy fon na wiki obsahuje úvodní Obecné zásady
- znaky: IPA vs. rozšířená česká abeceda
- přízvukové takty
- sdílené hlásky
Co a jak zachycujeme? (II)
- asimilace
- znělosti: běžné vs. tzv. “moravské”
- místa a způsobu
- zjednodušená výslovnost souhláskových skupin či naopak zdvojování hlásek
- proteze (nejen [v]!)
- ráz pouze nepřímo
Co a jak zachycujeme? (III)
- kvantita:
- dloužení i krácení
- patálie okolo [i/í]
- obecně: piš jak slyš – i cizí slova, vlastní jména, zkratky a zkratková slova…
- krátké varování pro fonetiky-začátečníky: naše uši nás klamou, máme tendenci slyšet ortoepičtěji (tj. vlastně blíže psané podobě, na niž jsme zvyklí), než mluvčí většinou vyslovují
Alignace vrstev ort a fon
- na wiki
- popsaná přímo v rámci návodu na transkripci stopy fon
- nebo samostatně v dokumentu Alignace vrstev ort a fon
- kontrola
- pomocí programu TransVer
- přehled funkcí
- návod na kontrolu alignace
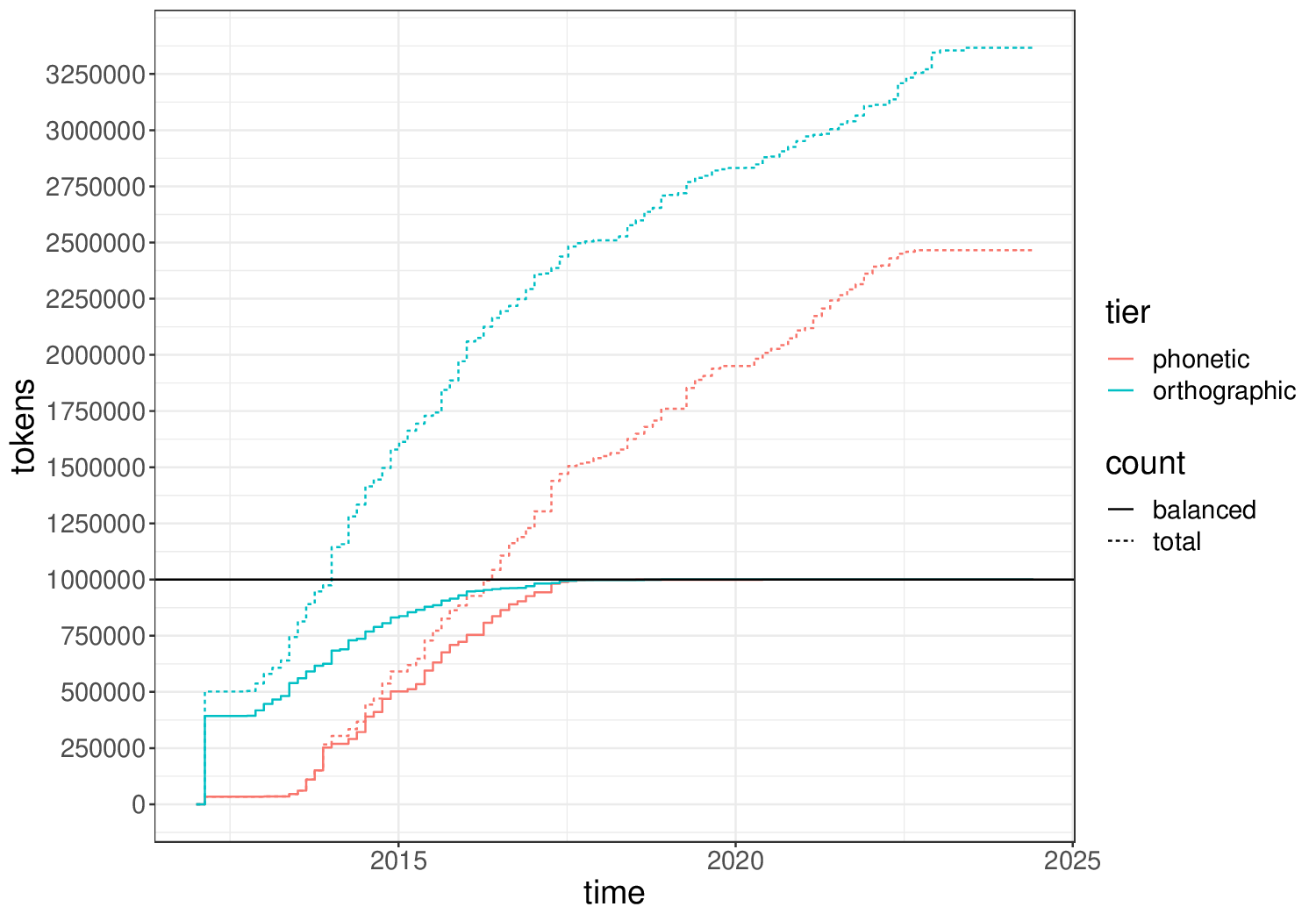
Budoucnost
- snad zrychlení procesu přepisu :)
- též větší konzistentnost
- s obojím by mohly pomoct metody založené na rozpoznávání řeči:
- místo překlopení by se na základě nahrávky a soupisu již existujících výslovnostních variant vygeneroval automatický přepis
- ten by pak editor jen kontroloval