Billions of words for the price of… lack of diversity:
Comparing web-crawled and traditional corpora
Václav Cvrček
David Lukeš
17th May 2019
Introduction
Corpus linguistics and the web
Last 15+ years – advent of web-crawled corpora
- (+) large (cf. the 14-billion-word iWeb corpus, Davies 2018)
- (+) cheap
- (+) families of “comparable” corpora: WaC family (Baroni et al. 2009), TenTen family (Jakubíček et al. 2013), Aranea family (Benko 2014)
- (+) DIY: AntCorGen (Anthony 2019) WebBootCat (Baroni et al. 2006)
- (-) lack of metadata (URLs only)
- (-) uncertainty regarding the composition (cf. Biber & Egbert 2016; Sharoff 2018)
Crucial question: What do the web corpora represent?
Comparison
Representativeness in corpus linguistics
Representativeness refers to the extent to which a sample includes the full range of variability in a population. (Biber 1993, p. 243).
Thus a corpus design can be evaluated for the extent to which it includes: (1) the range of text types in a language, and (2) the range of linguistic distributions in a language. (Biber 1993, p. 243).
\(\Rightarrow\) comparing corpora w.r.t. the variability they cover
Outline of the experiment
- compile a “traditional” corpus, as diverse as possible
- chart the space of variation with MDA
- take an opportunistic web-crawled corpus and make sample(s)
- project web corpus sample(s) onto MD space
- compare the range of variation in dimensions
Multi-dimensional analysis
Principles of multi-dimensional analysis (MDA)
Biber 1995; Biber & Conrad 2009
- systemic & functional variability (× random, sociolinguistic…)
- motivated by context & situation
- text production process involves interrelated choices
- dimensions of variation (“intratextual” perspective)
Methodology of MDA
- corpus compilation
- features: operationalization & extraction
- statistical analysis (factor analysis, FA) \(\rightarrow\) dimensions
- interpretation of results
MDA of Czech
CNC: MDA team

MDA of Czech
- inspiration from English and other languages
- expected challenges / highlights of MDA…
- … in Slavic languages – specific morphology, inflection, free word order
- … in Czech – situation bordering on diglossia (Bermel 2014): Literary × Common Czech
Cvrček, V., Komrsková, Z., Lukeš, D., Poukarová, P., Řehořková, A., & Zasina, A. J. (2018). From extra- to intratextual characteristics: Charting the space of variation in Czech through MDA. Corpus Linguistics and Linguistic Theory.
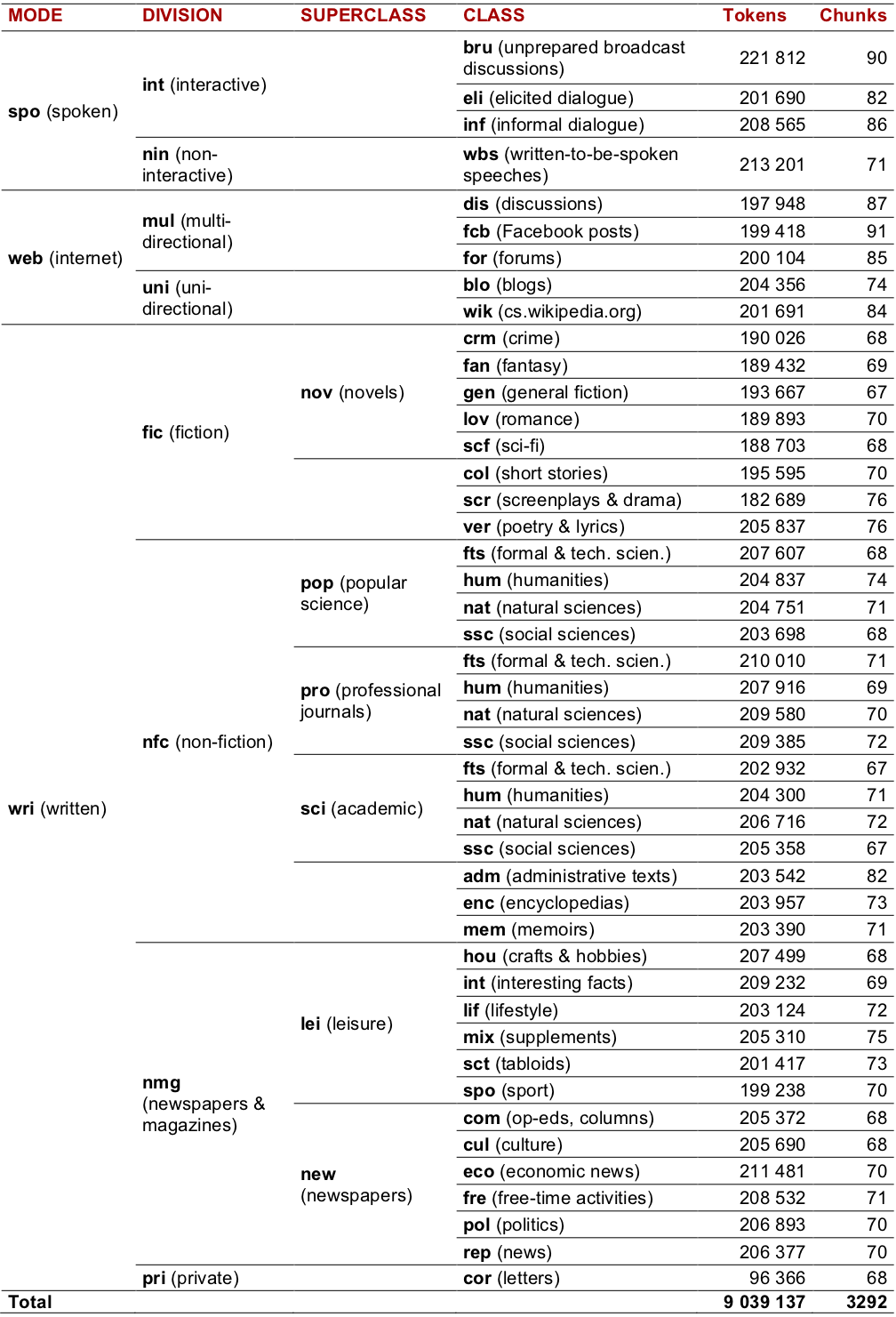
Data: Koditex corpus
- “traditional” carefully designed corpus covering all available text types
- guiding principles: diverse, contemporary, text length control
- text excerpts = chunks (not whole texts)
- 3 modes –
wri,spo,web- 8 divisions, 45 classes, \(\approx\) 200,000 words per class
| Category | # |
|---|---|
| Tokens | 10,8 M |
| Words (excl. punct.) | 9 M |
| Lemmata (types) | 204 K |
| Text chunks | 3 334 |
Koditex: composition
Koditex: internet communication
11 % of tokens, 421 text chunks
| division (class) | % tokens | chunks |
|---|---|---|
| Multi-directional (3) | 6.6 % | 263 |
| Uni-directional (2) | 4.5 % | 158 |
- posts (fb, forums, discussions) – aggregated according to author and time into chunks of 2000–5000 words
- blogs, Wikipedia – continuous samples of 2000–5000 words
Features and their operationalization
Originally 140+ features, final list 122, e.g.:
- phonetics – narrowing é > í, vowel breaking ý > ej, average word length…
- morphology – freq. of cases, numbers, moods, tenses…
- derivation – adjectives denoting similarity, verbal nouns, diminutives…
- lexicon – indefinite pronouns, reporting verbs, verbs of thinking, semantically bleached nouns…
- pragmatics – contact expressions, fillers, intensifiers, downtoners…
- syntax – types of attributes, clusters of POS, types of dependent clauses…
- text/discourse – questions, phraseology, word repetition…
Statistical evaluation: Factor analysis
Interpretation: Dimensions of variability
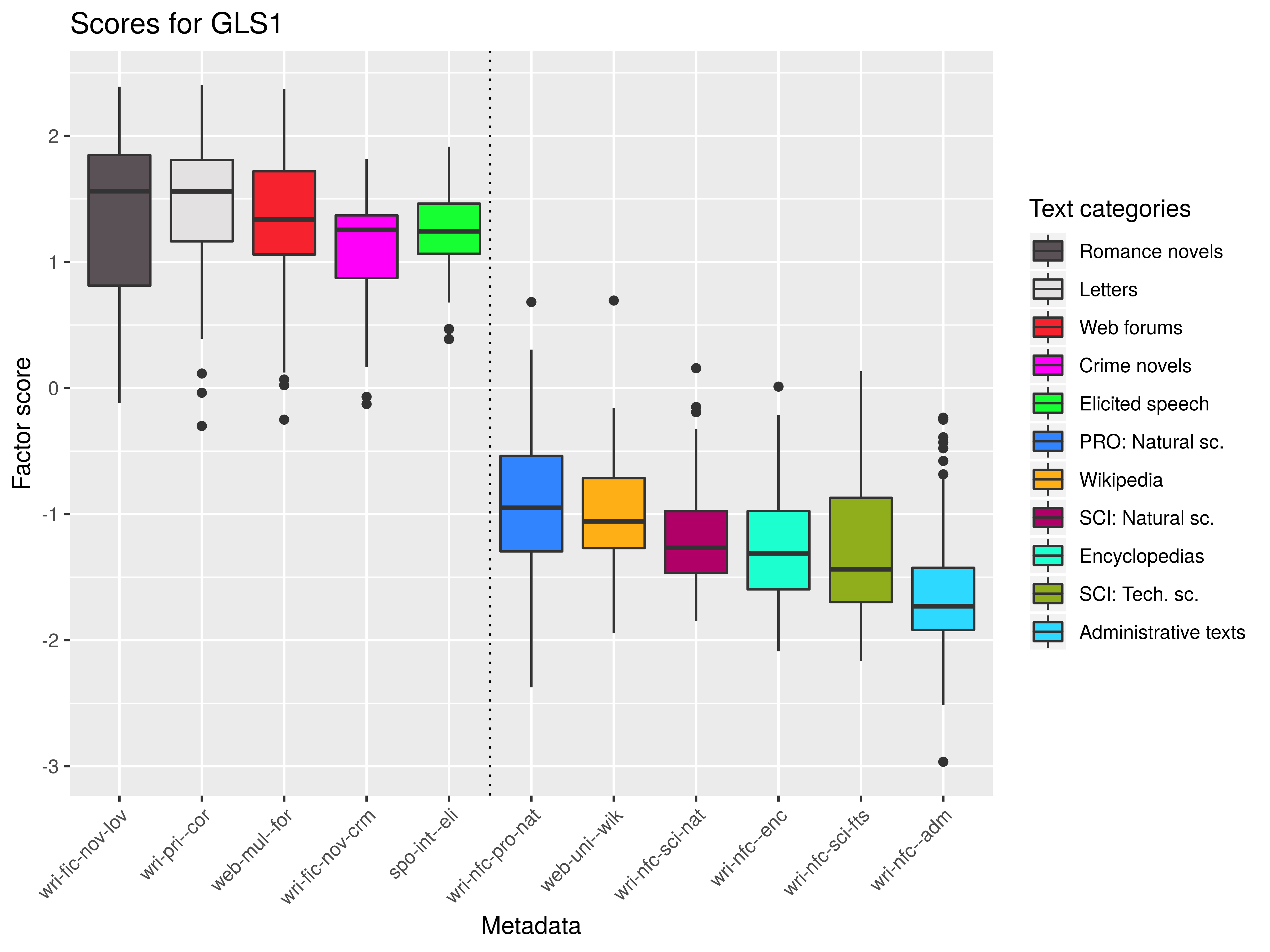
- dynamic (+) × static (-): verbal/clausal × nominal/phrasal constructions
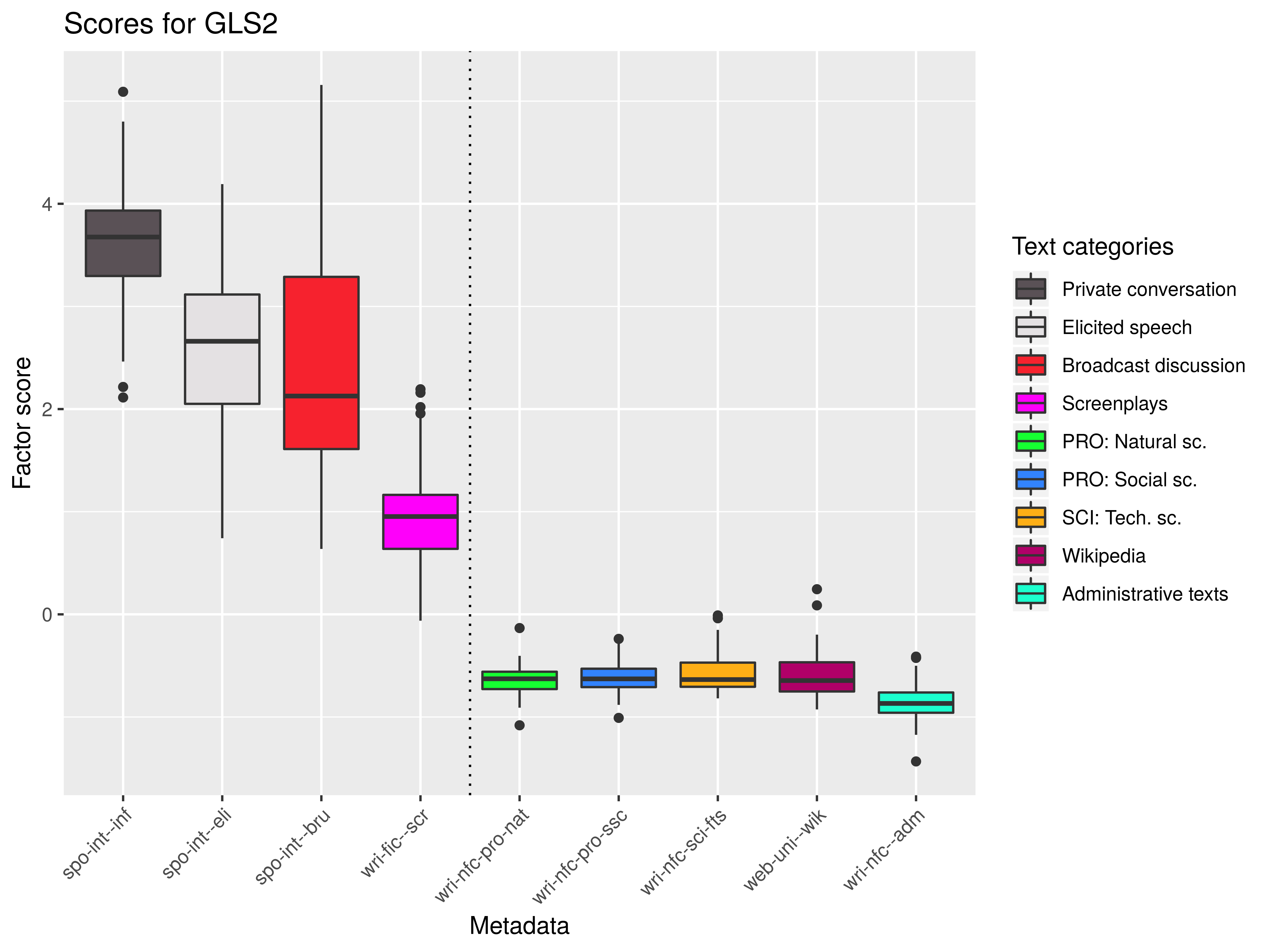
- spontaneous (+) × prepared (-): hit-and-miss redundant coding × carefully worded formulations
- higher (+) × lower (-) level of cohesion: propensity to use connecting devices and means of intratextual reference
- polythematic (+) × monothematic (-): lexically rich × repetitive texts
- higher (+) × lower (-) amount of addressee coding: explicit references to communication partners
- general (+) × particular (-): description of general qualities × discussion of particular referents
- prospective (+) × retrospective (-): present and future tense, non-narrative × past tense, narrative
- attitudinal (+) × factual (-): degree of explicit epistemic certainty, higher × lower amount of hedging
Dim 1: dynamic (+) × static (-)
Dim 2: spontaneous (+) × prepared (-)
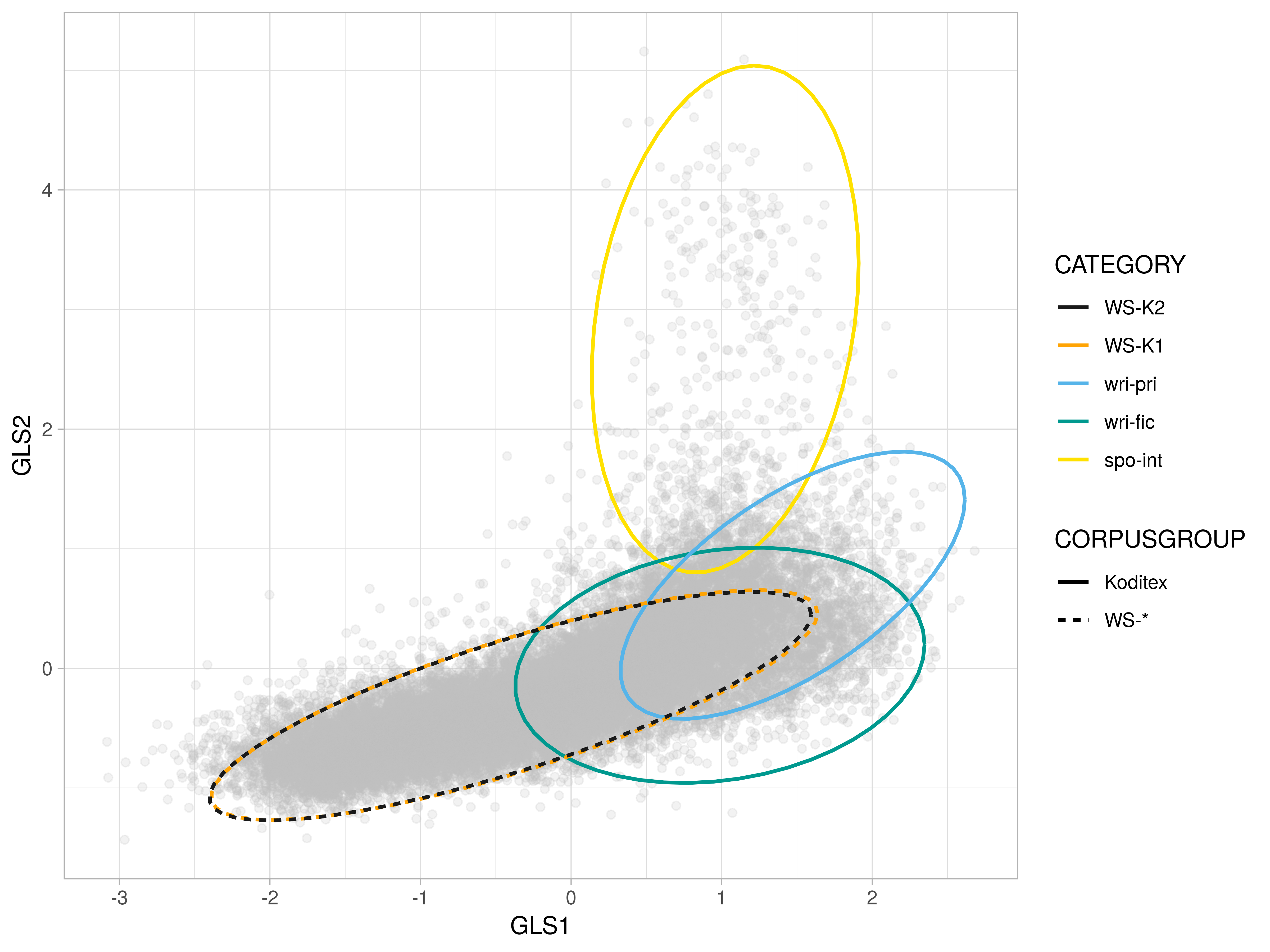
2D-plot: dim 1 and dim 2
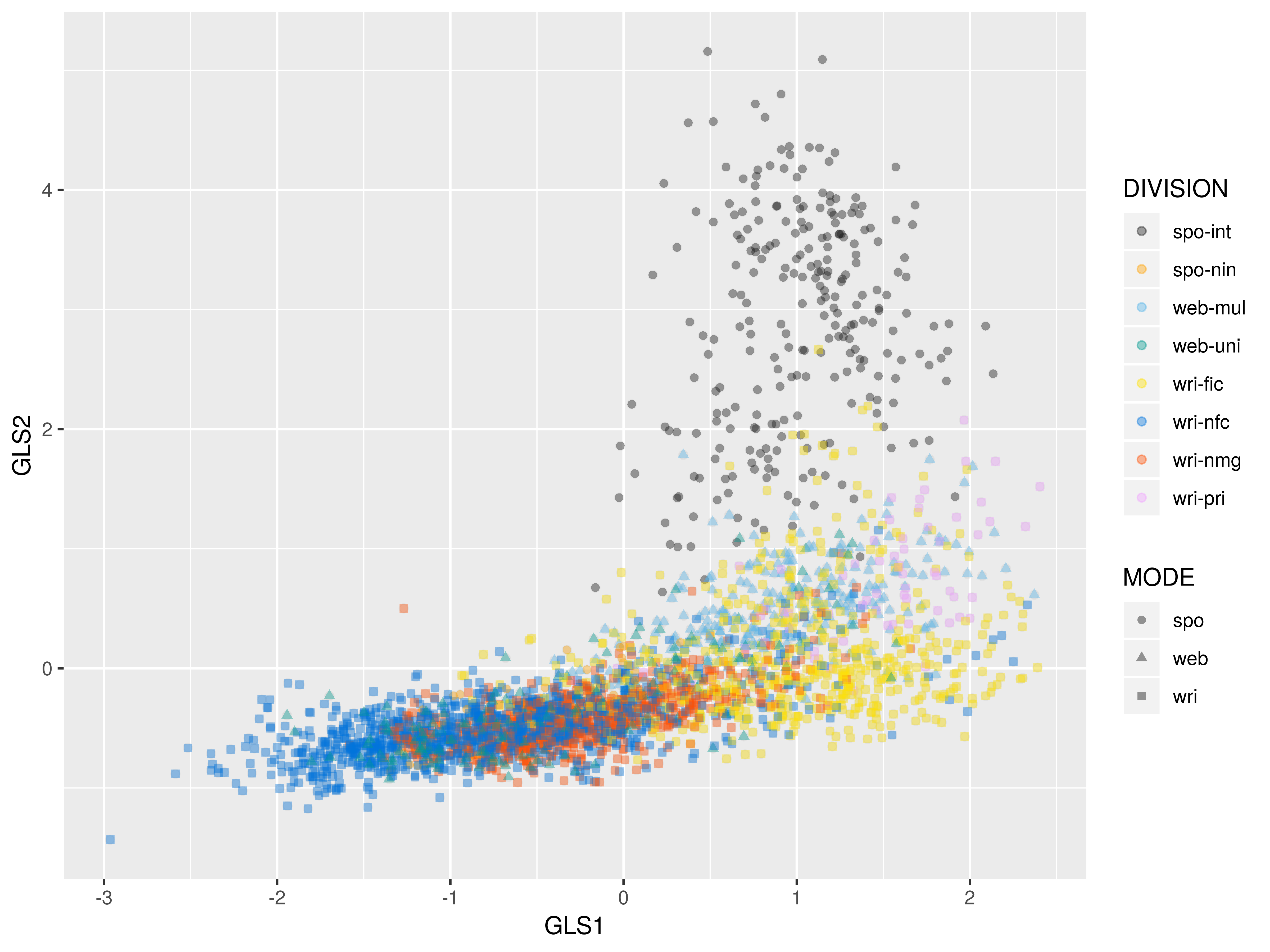
Sampling the Araneum Bohemicum corpus
Araneum Bohemicum
- part of the Aranea Project (Benko 2014, 2016)
- Araneum Bohemicum Maximum 15.04
- crawled in several sessions during May and June 2013
- yielded 9.5 million documents (web pages)
- approx. 5.5 billion tokens of text
- after filtering and deduplication \(\Rightarrow\) 5.2 million documents and 3.3 billion tokens
- opportunistic design
- representation of “searchable” web
WebSample
Two samples (named WS-K1 and WS-K2), based on Araneum Bohemicum
- two batches with 5000 text excerpts each
- text length distributions modeled after Koditex
- subsequent processing analogous to Koditex texts
Comparison: Koditex vs. WebSample
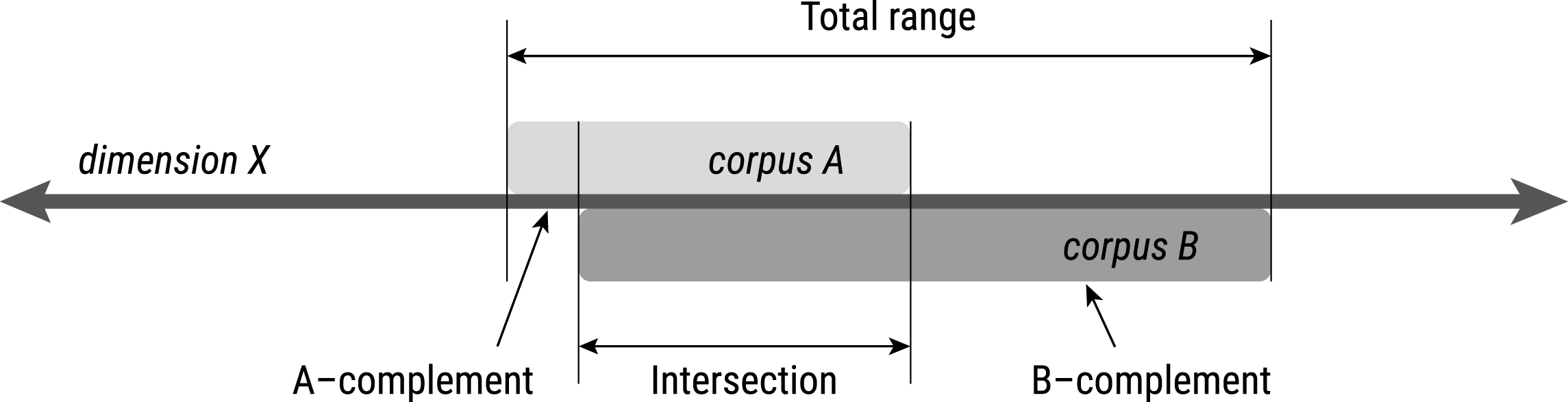
Comparison methodology
- evaluate the set of 122 linguistic features assembled for the original MD model on the WS-K1 and WS-K2 batches
- calculate “positions” of WS chunks in MD space
- comparison of the ranges covered by Koditex vs. WS
- for each dimension individually
- aggregated across dimensions
- 2-D visualization
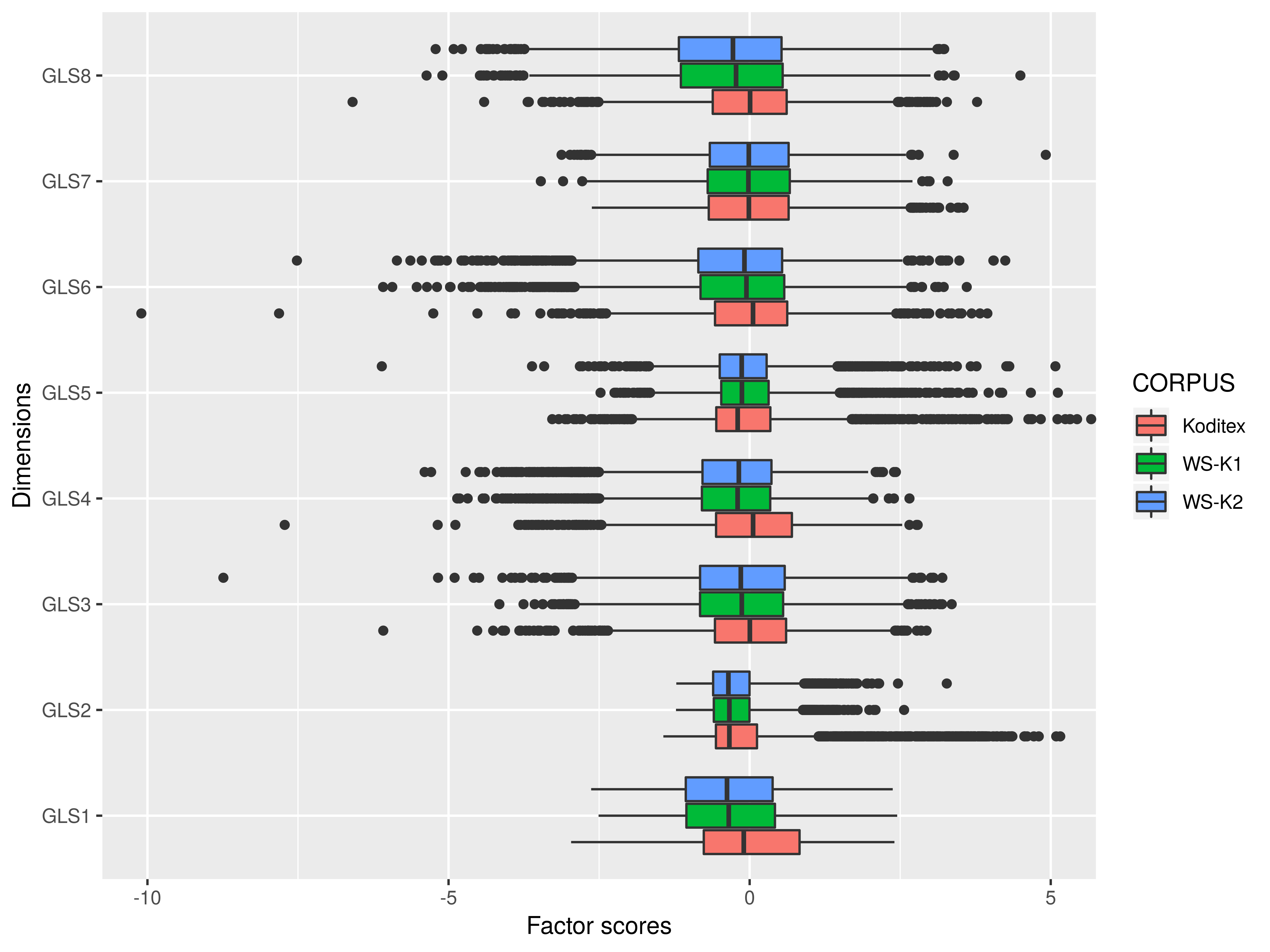
Per-dimension comparison
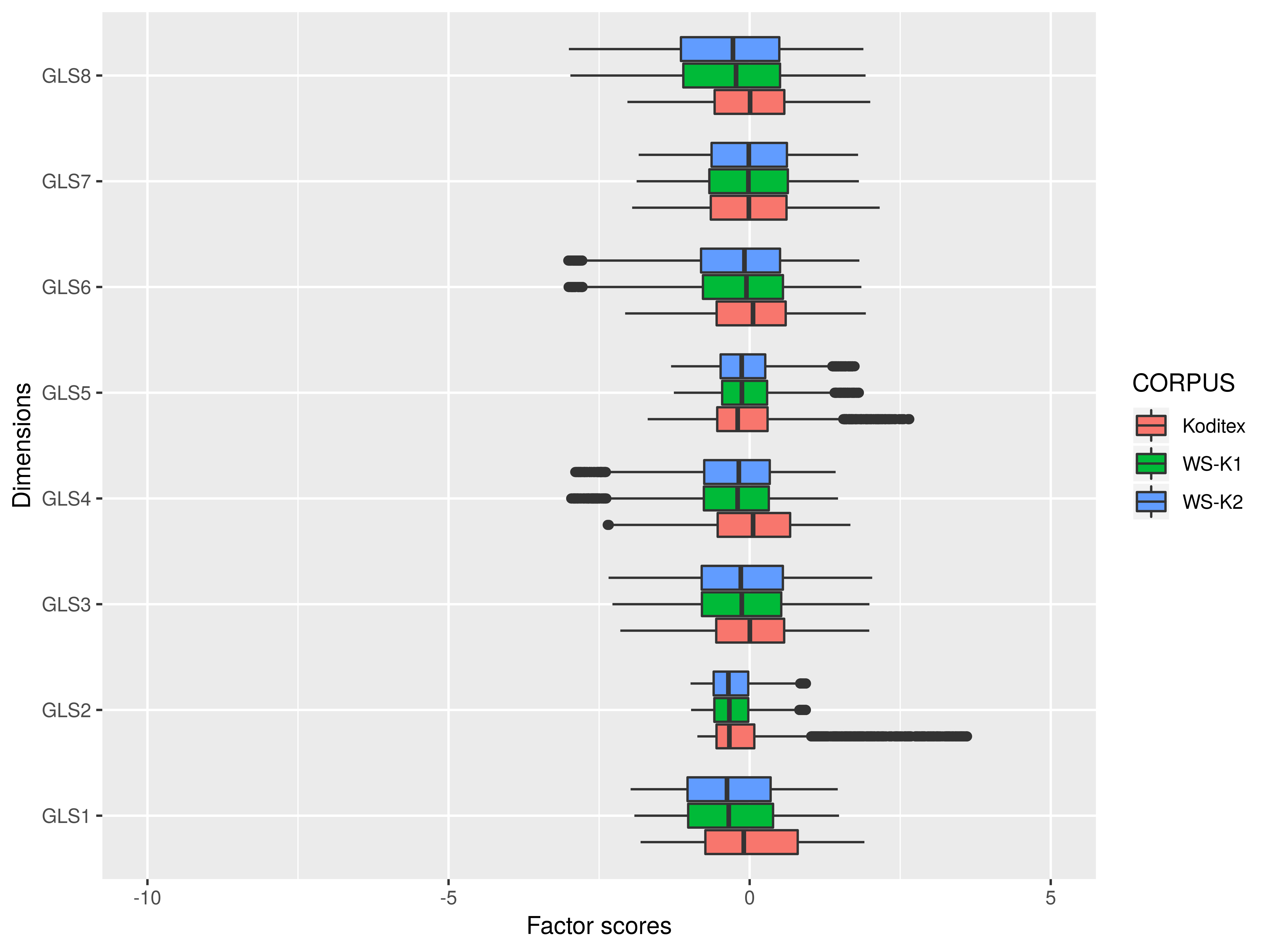
Per-dimension comparison (2nd–98th %tile)
Interpretation
- the position of the median does not seem to vary substantially
- the dispersions are significantly different (tests of homogeneity of variances – Bartlett, Fligner-Killeen – show that the differences are significant, p < 0.01)
Average proportions of shared and corpus-specific variation ranges:
| WS batch | Intersection with Koditex | Koditex complement | WS complement |
|---|---|---|---|
| WS-K1 | 78.00% | 14.60% | 7.39% |
| WS-K2 | 77.10% | 15.10% | 7.82% |
Major differences
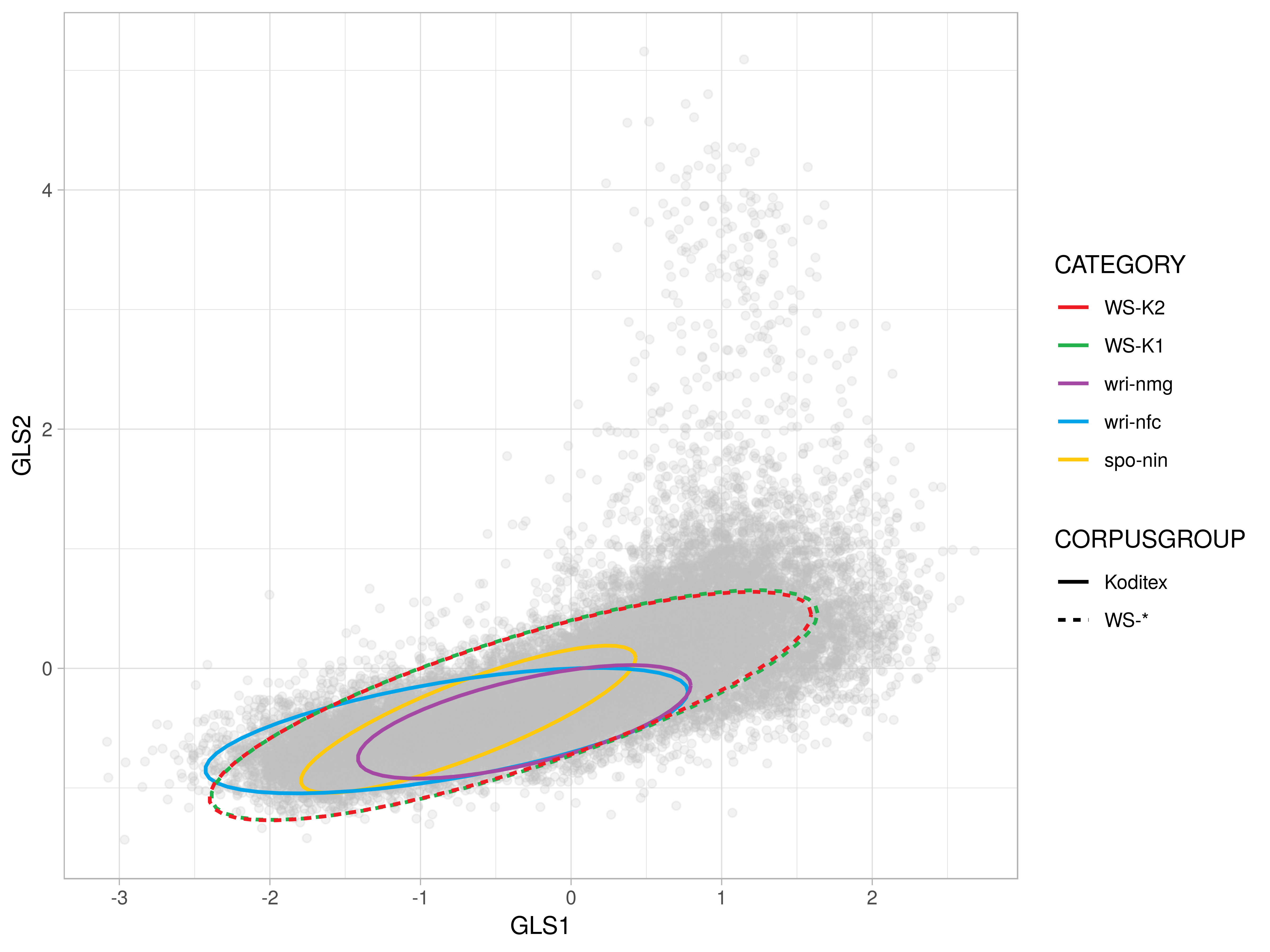
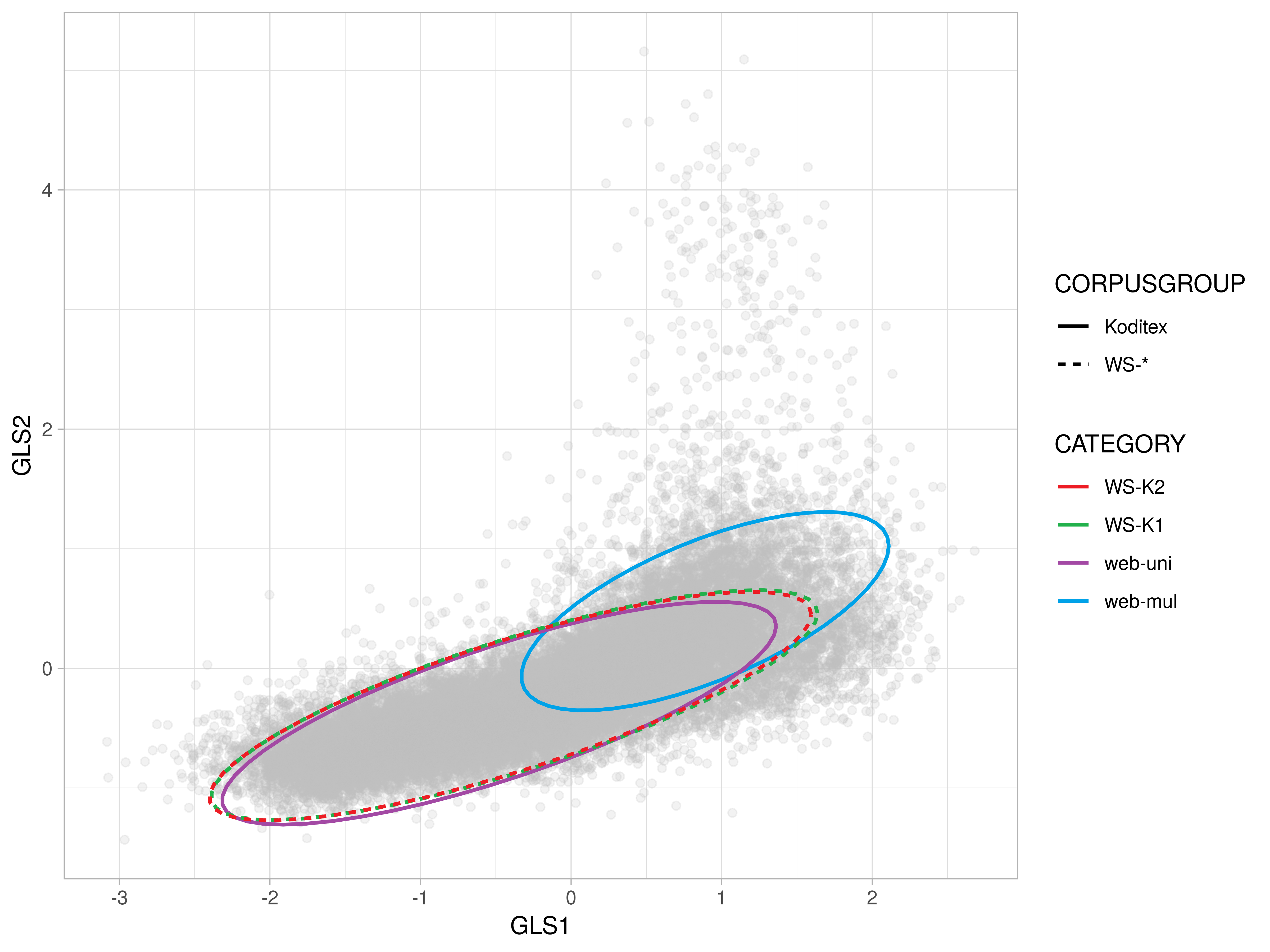
- Dim 1: Koditex brings in the dynamic extreme, whereas WSs add texts widening the spectrum towards the static pole
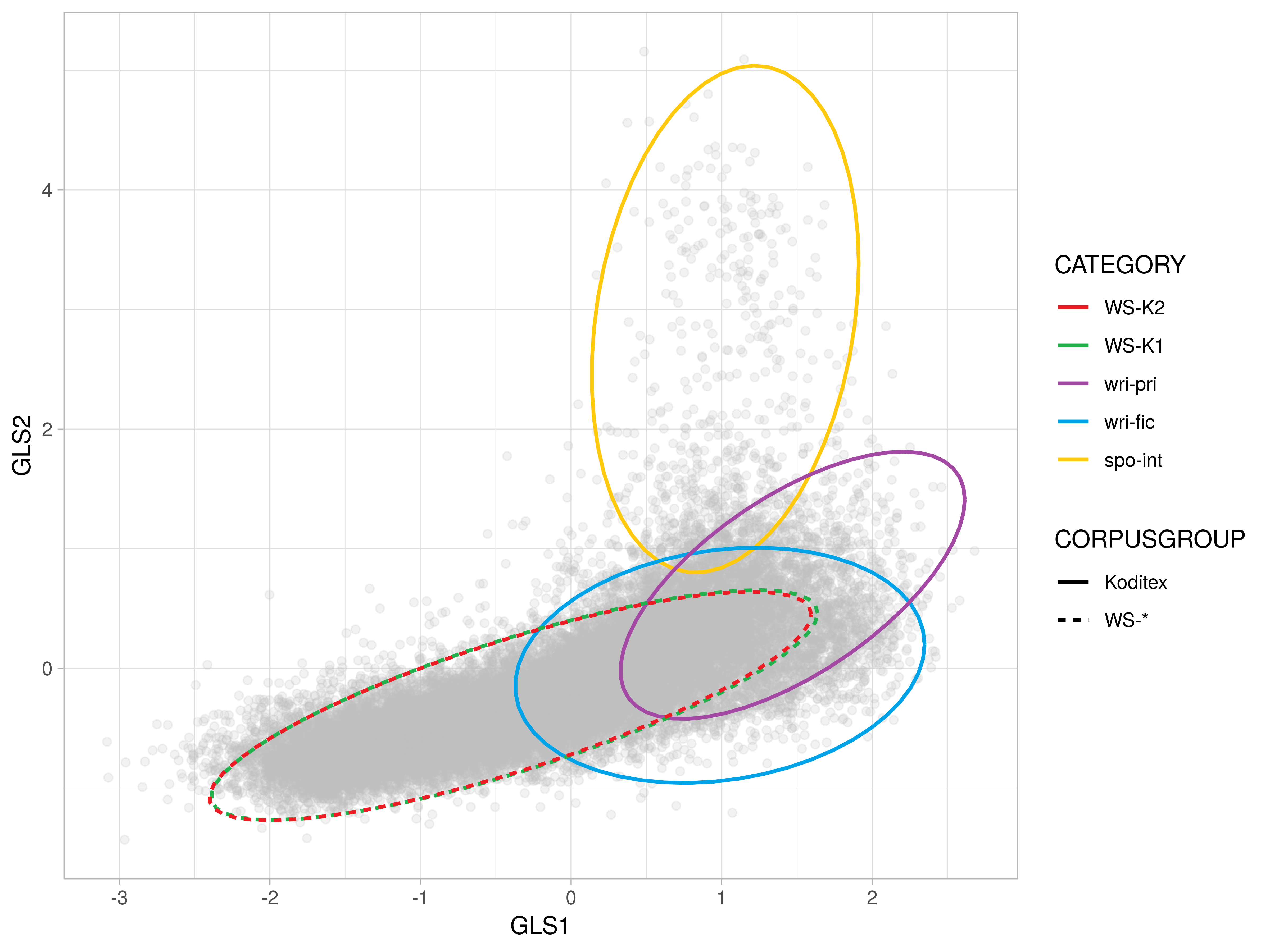
- Dim 2: the most salient difference – the Koditex complement introduces a range of texts on the spontaneous extreme from the spoken interactive category (
spo-int) - Dim 5: variation of WSs is fully covered by Koditex texts with more explicit addressee focus, mainly dialogues in fiction
- Dim 8: WSs in general tend to lean towards the factual extreme
2-D Comparison I: fully covered by WS
2-D Comparison II: web genres
2-D Comparison III: Koditex unique
Conclusions
Conclusions I
- large overlap in text categories which are easy to obtain on the web as well as when building an offline-text corpus (journalistic and non-fiction texts)
- web-crawled texts occasionally tend towards their own distinctive regions of the MD space (static, less cohesive, factual and focused on particular referents)
- unique text categories occupying distinct areas are only found in the traditional Koditex corpus – spoken informal (intimate) discourse, written private correspondence and some types of fiction (dynamic and addressee-oriented)
- …and more in Cvrček et al. forthcoming
Conclusions II
Main take-aways:
- Some text categories cannot be substituted by general web-crawled data and represent an irreplaceable and unique source of linguistic variation.
- Web communication has its specificities and web corpora are useful, but they should not be used as an argument against investing in more expensive sources of data.
Follow-up questions:
- What about other languages?
- English as the lingua franca of the web may be idiosyncratic.
References
- Anthony, L. (2019). AntConc (Version 3.5.8). Retrieved from http://www.laurenceanthony.net/software
- Baroni, M., Bernardini, S., Ferraresi, A., & Zanchetta, E. (2009). The WaCky wide web: a collection of very large linguistically processed web-crawled corpora. Language Resources and Evaluation, 43(3), 209–226.
- Baroni, M., Kilgarriff, A., Pomikálek, J., & Rychlý, P. (2006). WebBootCaT: a web tool for instant corpora. Proceeding of the EuraLex Conference, 123–132.
- Benko, V. (2014). Aranea: Yet another family of (comparable) web corpora. International Conference on Text, Speech, and Dialogue, 257–264. Springer.
- Benko, V. (2016). Two Years of Aranea: Increasing Counts and Tuning the Pipeline. LREC, 4245–4248.
- Bermel, N. (2014). Czech Diglossia: Dismantling or Dissolution? In J. Arokay, J. Gvozdanovic, & D. Miyajima (Eds.), Divided Languages? Diglossia, Translation and the Rise of Modernity in Japan, China, and the Slavic World (1st ed., pp. 21–37). Dordrecht: Springer International Publishing.
- Biber, D. (1993). Representativeness in corpus design. Literary and Linguistic Computing, 8(4), 243–257.
- Biber, D. (1995). Dimensions of Register Variation: A Cross-Linguistic Comparison. Cambridge, England: Cambridge University Press.
- Biber, D., & Conrad, S. (2009). Register, Genre, and Style. Cambridge, England: Cambridge University Press.
- Biber, D., & Egbert, J. (2016). Register Variation on the Searchable Web: A Multi-Dimensional Analysis. Journal of English Linguistics, 44(2), 95–137.
- Cvrček, V. et al. (2018). From extra- to intratextual characteristics: Charting the space of variation in Czech through MDA. Corpus Linguistics and Linguistic Theory. [Ahead of print]
- Cvrček, V., Komrsková, Z., Lukeš, D., Poukarová, P., Řehořková, A., Zasina, A. J., & Benko, V. (forthcoming). Comparing web-crawled and traditional corpora.
- Davies, M. (2018). The 14 Billion Word iWeb Corpus. Retrieved from https://www.english-corpora.org/iweb/
- Jakubíček, M., Kilgarriff, A., Kovář, V., Rychlý, P., & Suchomel, V. (2013). The tenten corpus family. 7th International Corpus Linguistics Conference CL, 125–127.
- Revelle, W. (2018). psych: Procedures for Psychological, Psychometric, and Personality Research.
- Sharoff, S. (2018). Functional Text Dimensions for the annotation of web corpora. Corpora, 13(1), 65–95.
Acknowledgments
This research was supported by the ERDF project Language Variation in the CNC no. CZ.02.1.01/0.0/0.0/16_013/0001758.
It builds upon work made possible by the Czech National Corpus project (LM2015044) funded by the Ministry of Education, Youth and Sports of the Czech Republic within the framework of Large Research, Development and Innovation Infrastructures.
