Korpusový manažer EXAKT – quickstart
Table of Contents
1 Instalace, nastavení a připojení ke korpusu
Korpusový manažer EXAKT nedisponuje webovým rozhraním, nýbrž je potřeba si ho nainstalovat lokálně, podobně jako Bonito.
- Pokud nemáte nainstalovanou Javu, začněte s ní.
- Poté si stáhněte a nainstalujte sadu nástrojů pro práci s korpusy ve
formátu EXMARaLDA. Obsahuje tři programy, z nichž nás v tuto chvíli
zajímá jen ten třetí:
- PartiturEditor slouží k vytváření a editaci přepisů (podobně jako ELAN nebo Transcriber)
- CoMa slouží ke "zkorpusování" sady samostatných sond
- EXAKT slouží k prohledávání korpusu vytvořeného v předchozím bodu
- Otevřete EXAKT (během instalace by se vám měla vytvořit ikona na ploše) a odsouhlaste žádost o vytvoření souboru, kam si můžete ukládat často používané regulární výrazy.
- Klikněte na Edit → EXAKT preferences… a na záložce Fonts si rovnou nastavte větší velikost písma pro zobrazení konkordance (alespoň 16), případně i jiný font (Arial).
- Klikněte na File → Open remote corpus…
- Pole Corpus URL, Username a Password vyplňte podle pokynů v zaslaném e-mailu a klepněte na OK. Chvilku potrvá, než se korpus nahraje (progress bar je vlevo nahoře); toto nahrání je potřeba zopakovat při každém novém sezení.
- Na stejnou kombinaci uživatelského jména a hesla se vás počítač pravděpodobně zeptá ještě jednou, a to ve chvíli, kdy si poprvé rozkliknete (dvojitým klikem na řádek v konkordanci, viz níže) detail nějaké části sondy. Když v dialogu zaškrtnete políčko Zapamatovat pověření, už by se vás neměl ptát znovu.
- S tím souvisí poslední (leč důležitá) technická drobnost: ve chvíli, kdy si takto rozkliknete detail sondy, stáhne se k ní rovnou celá nahrávka. Ta má ve formátu .mp3 většinou 10-15MB, případně méně, ojediněle naopak až kolem 20-30MB. V době dnešního rychlého internetu se to snese, ale důrazně bych to nedoporučoval v situacích, kdy máte na datový přenos nějaký nízký limit (např. připojení na chalupě přes internet v chytrém mobilu).
2 Rozhraní EXAKTu
Rozhraní EXAKTu vypadá následovně:
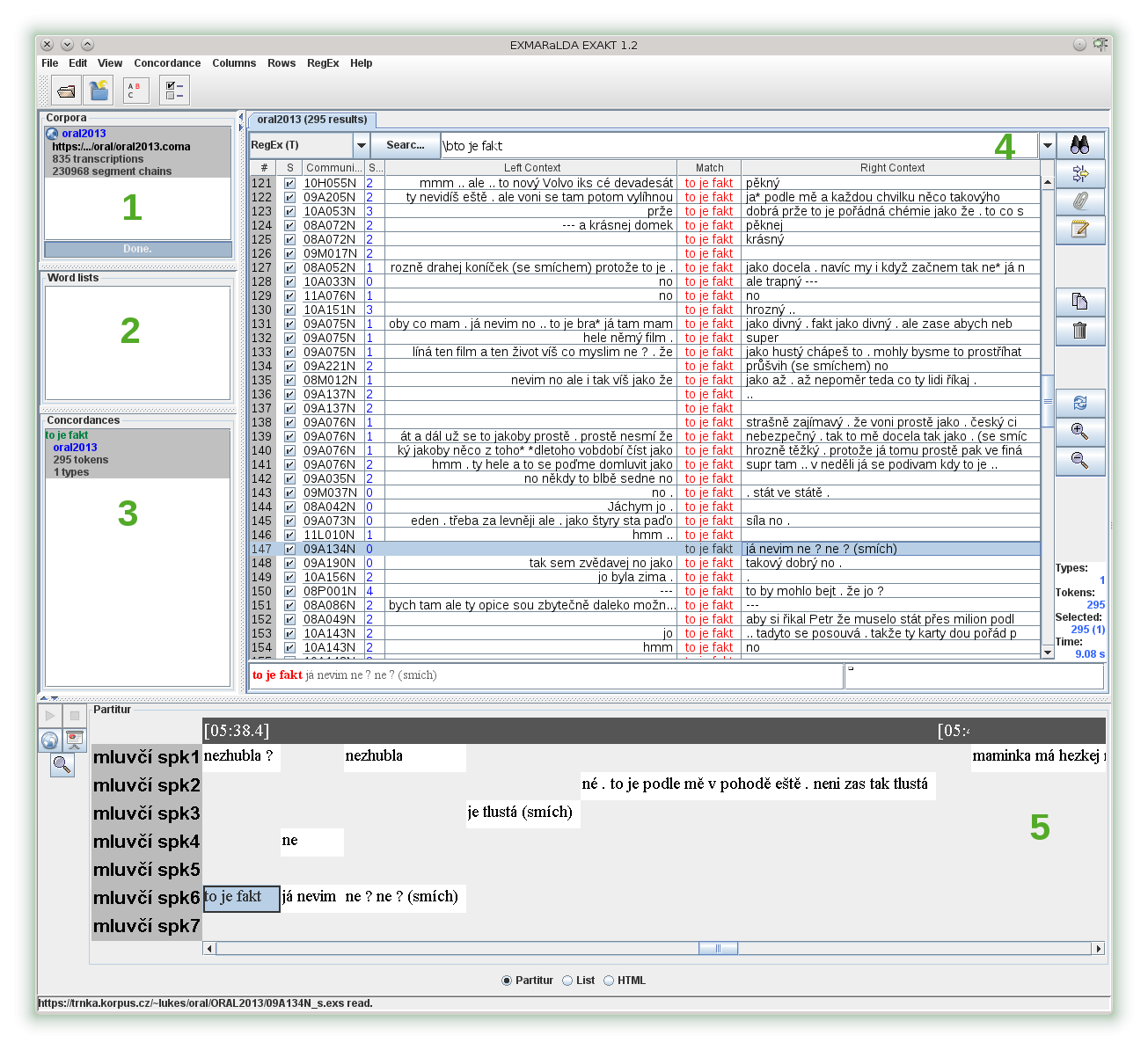
Můžeme ho rozdělit na pět částí (viz zelená čísla na obrázku):
2.1 Corpora – Aktivní korpusy
Zde se vám ukazují korpusy, které máte v manažeru zrovna nahrané. Zatím to bude jen ORAL 2013, časem možná přibude možnost otevřít si pracovní verzi ORTOFONu.
2.2 Word lists – Frekvenční seznamy
Na frekvenční analýzu se EXAKT moc nehodí, umí jen jednoúrovňovou v podobě wordlistu a i tu jsem vypnul, protože zpomaluje indexování při nahrávání korpusu a beztak je na to lepší KonText/Bonito, s kterými to už všichni umíme. Pro ORTOFON ale asi k dispozici budou, protože pracovní verze nebude přes manatee dostupná.
2.3 Concordances – Seznam otevřených konkordancí
Konkordancí můžete mít v podokně č. 4 otevřeno libovolné množství (viz níže), zde je jejich přehled včetně počtu nalezených dokladů ("295 tokens") a počtu typů na pozici KWICu (bere se v úvahu celý match).
2.4 Hlavní okno – aktivní konkordance
V tomto hlavním okně se zobrazuje konkordance ve velmi podobném formátu jako
v KonTextu/Bonitu. Dotaz se zadává do okýnka nahoře, přičemž v seznamu
nalevo je třeba zvolit typ prohledávání RegEx (T) (měl by být zvolený
implicitně; o vyhledávání viz níže).
Konkordance obsahuje informace o sondě, KWIC a levý a pravý kontext (množství kontextu lze upravit pomocí tlačítek s lupou v liště napravo). Podle všech těchto parametrů lze třídit kliknutím na příslušné políčko v hlavičce tabulky. Pozor, levý kontext se třídí retrográdně – EXAKT sám o sobě nemá potuchy o hranicích tokenů.
Úplně vlevo jsou navíc u každé položky zaškrtávací políčka; když je u některých záznamů odškrtnete a poté kliknete na ikonu koše vpravo, vyřadíte tím záznamy z konkordance (můžete si ji takto ručně pročistit). Ovlivnit stav zaškrtávacích políček lze také pomocí tlačítka Filter v liště napravo, které umožňuje konkordanci filtrovat podle jednotlivých sloupců. Vše zresetovat do původního stavu (= všechno vybráno) lze pomocí menu Rows → Select all.
Kromě vyřazování záznamů lze konkordanci ještě anotovat, přičemž EXAKT anotacím říká Analysis (Annotation pro něj je už v průběhu kompilace korpusu vytvořená a prohledávatelná anotace). Klikněte na Columns → Add analysis…, vyberte pro analýzu název a zvolte její typ. Analýza se vám zobrazí jako další kolonka v konkordanci, v níž ovšem můžete obsah políček měnit. Pokud jste jako typ zvolili Free, můžete do kolonky volně psát; u typu Closed category list vybíráte z kategorií, které jste si předem nadefinovali, a typ Binary je zjednodušenou verzí toho předchozího, kde jsou jen dvě kategorie.
Když už jste si dali práci s pročištěním a oanotováním konkordance, dává smysl, že si ji můžete i vyexportovat (uložit na disk) pomocí Concordance → Save concordance, a během nějakého dalšího sezení ji znovu otevřít a dále na ní pracovat pomocí Concordance → Open concordance.
Konkordancí můžete mít souběžně otevřených několik: stačí kliknout na menu Concordance → New concordance a v podokně konkordancí se vám vytvoří nová záložka. Mezi výsledky jednotlivých dotazů lze tím pádem pohodlně přepínat.
Pokud na řádek v konkordanci jednou kliknete, zobrazí se vám v okýnku pod ní delší kontext promluvy daného mluvčího, v níž je KWIC obsažen. Pokud na něj kliknete dvakrát, otevře se příslušná část nahrávky v podokně Partitur (viz následující oddíl) ve formátu časové osy, v níž má každý mluvčí v konverzaci svou vlastní transkripční vrstvu.
Douška na závěr: EXAKT je implicitně nastaven tak, aby okolo 10000 nalezených dokladů zastavil hledání (aby netrvalo zbytečně dlouho). Pokud chcete najít opravdu všechny výskyty, je potřeba v menu Edit → EXAKT Preferences… na záložce Performance zaškrtnout políčko Unlimited u první položky. Stejně tak lze na této záložce ovlivnit maximální zobrazitelný kontext v konkordanci a na časové ose (partituře).
2.5 Partitur – Časová osa
Partitura nabízí přehledné zobrazení výsledků hledání zasazených do kontextu celé konverzace, z níž pocházejí. Pomocí horních dvou tlačítek v tomto podokně lze spustit/zastavit přehrávání zvuku; tlačítko se zeměkoulí slouží k vygenerování partitury v HTML formátu, která je členěná i vertikálně a tedy možná pohodlnější na čtení; tlačítko s lupou ke zvětšení písma (znovu nutné). Kolik se z celého přepisu zobrazí závisí na nastavení popsaném v předchozím odstavci.
Kromě partitury nabízí toto podokno ještě dvě jednodušší zobrazení, List a HTML. V nich je nahrávka členěna do řádků po jednotlivých promluvách.
Připomínám, že ve chvíli, kdy si rozkliknete u některého konkordančního řádku partituru, se vám automaticky stáhne celý zvukový soubor patřící k sondě.
3 Vyhledávání
Nyní k samotnému vyhledávání. EXAKT je v tomto ohledu primitivnější nástroj
než manatee, nepracuje s tokenizací na úrovni slov – vyhledává rovnou v
celých promluvách (tzv. segment chains). Promluva je definována jako
souvislá sekvence na sebe těsně navazujících segmentů v rámci vrstvy jednoho
mluvčího. Např. v níže uvedeném obrázku je u mluvčího spk2 jedna promluva
no .. Leni tu mám ty . vzorniky víš ? různé, další tu mám z jedne firmy
apod. POZOR, promluva je tedy do jisté míry technická jednotka (takže by
asi bylo lepší neříkat tomu promluva, ale jiný krátký a úderný termín mě
nenapadá…).

Nevýhodou je, že nelze hledat přes hranice promluv1 – kdybych tedy třeba
hledal sekvenci slov různé tu mám, tak mi EXAKT příslušné místo v projevu
mluvčího spk2 v předchozím obrázku nenalezne, neboť obě části, které by
dohromady s dotazem matchovaly (různé a tu mám) jsou odděleny hranicí
promluvy. Na druhou stranu, s KonTextem je to v tomto ohledu z bláta do
louže, protože tam bychom zase ve vertikále měli mezi různé a tu mám
vmezeřený vstup druhého mluvčího.
Jestliže EXAKT nepracuje s explicitní tokenizací, je třeba využít znalostí o podobě přepisu k tokenizaci implicitní. V našem případě víme, že se můžeme spolehnout na to, že budou jednotlivá slova vždy oddělena jednou mezerou. Vybaveni touto znalostí můžeme s pomocí regulárních výrazů korpus prohledávat podobně volně jako v KonTextu (byť možná méně pohodlně).
Pozor, v KonTextu/manatee/CQL se regulární výrazy používají vždy pouze pro specifikaci dané pozice (slova); v EXAKTu nic jako pozice nemáme, takže regulárními výrazy budeme vždy rovnou vyjadřovat i celou sekvenci slov – budou v nich tedy na rozdíl od KonTextu zahrnuty právě i ony mezery.
3.1 Regulární výrazy
NB: Příklady vyhledávacích dotazů v této sekci jsou
<ohraničeny dvěma zobáčky>, přičemž tyto zobáčky už do zadání samotného
dotazu nepatří.
Když do hledacího boxu v podoknu konkordance napíšu jen <to>, najde mi to i
výskyty, kde je "to" jen podřetězcem nalezeného slova – "auto", "katovna",
"topinambur" apod. Můžu tedy zkusit hledat < to > ohraničené z obou stran
mezerami. To už budu úspěšnější, ale stále mi vypadnou všechny výskyty "to"
na začátcích promluv, kde není z levé strany mezera (naopak "to" na koncích
promluv z pravé strany mezeru mají, takže tam je vše v pořádku).
Abych našel opravdu všechna "to", která jsou samostatnými slovy, musím
použít speciální značku, kterou se v regulárních výrazech označují
hranice slov: <\b>. Když se tedy EXAKTu zeptám na <\bto\b>, dostanu už
opravdu úplně všechny.2 V praxi je to <\b> potřeba pouze na začátku
dotazu – ve zbytku už jej lze v našem případě nahradit mezerami, takže
dotazy <\bto\b> a <\bto > jsou ekvivalentní (a ten druhý ušetří trochu
psaní).
Co když chci hledat "to" na začátcích promluv? Od toho je tu stříška,
<^>. Dotaz <^to > nalezne všechna "to", kterými promluvy
začínají. Podobným způsobem funguje na konce promluv dolar, nesmíme ovšem
zapomenout na příslušné mezery: < to $>. (Doplnit <\b> je v obou
případech možné, ale redundantní – víme, že hranice promluvy je zároveň
hranicí slova.)
Když chci hledat sekvenci více slov, oddělím je jednoduše mezerami:
< to je fakt > najde všechny výskyty "to je fakt" uprostřed promluv,
<^to je fakt > na začátcích a <\bto je fakt > na libovolném místě.
Jak specifikovat, že na daném místě v hledaném výrazu může být libovolný token? Stačí si vzpomenout, že v regulárních výrazech lze pomocí hranatých závorek specifikovat celé množiny znaků:
<\bto [abcd]>najde "to" následované slovem začínajícím (všimněte si, že po uzavírající hranaté závorce není mezera) na "a", "b", "c" nebo "d"<\bto [abcd]+ >najde "to" následované slovem složeným (zde už mezera je) pouze z těchto čtyř písmen:<+>značí, že se předchozí znak (či libovolný kombinace znaků ze skupiny definované pomocí závorek) může libovolněkrát (ale alespoň jednou) opakovat<*>značí, že se předchozí znak (či libovolná kombinace znaků ze skupiny definované pomocí závorek) může libovolněkrát (klidně i nulakrát) opakovat- lze stanovit i konkrétní požadované rozmezí pro počet opakování:
<a{3,5}>matchuje "aaa", "aaaa" a "aaaaa",<a{5,}>matchuje pět "a" v řadě za sebou a víc,<a{,5}>matchuje pět "a" v řadě za sebou a míň
- lze použít i negaci – zde se v nové roli uplatní stříška, která má
bezprostředně po otevírající hranaté závorce význam negace:
<\bto [^abcd]+ >najde "to" následované slovem, v němž se nesmí vyskytovat ani jedno ze čtyř uvedených písmen - teď už tedy dokážeme zapsat i libovolný token – je to sekvence
čehokoli, co nejsou mezery, příslušně oddělená mezerami nebo pomocí
<\b>:<\b[^ ]+ > - pokud chceme hledat pouze slova (tj. vynechat tokeny jako je pauza
apod.), můžeme využít speciálního znaku
<\p{L}>, který označuje libovolné písmeno:<\b\p{L}+ >tedy najde libovolné slovo (ale ne pauzu, otazník apod.) - existují také znaky pro libovolné velké písmeno
<\p{Lu}>("Letter uppercase") a malé písmeno<\p{Ll}>("Letter lowercase") – mohou se hodit, kdyby někdo chtěl např. hledat anonymizační značky - negace (doplňky) těchto množin obdržíte tak, že místo
<\p{...}>použijete<\P{...}>
Jinak umí EXAKT při hledání vše, co umí regulární výrazy v Javě (protože je přímo používá). I veškeré znalosti z regulárních výrazů v CQL je možné aplikovat3, jen je třeba mít neustále na paměti, že EXAKT na rozdíl od manatee nehledá v sekvencích ohraničených tokenů, ale v celých jednotlivých promluvách.
Na závěr je dobré připomenout, že pokud chcete vyhledávat nějaký znak, který
má v regulárních výrazech speciální význam (*, +, ., ? …), je potřeba v
dotazu tento speciální význam zrušit tím, že před ním přidáte zpětné
lomítko. Např. všechny krátké (".") a střední ("..") pauzy v ORALu 2013
tedy vyhledáme dotazem < \.{,2} >.
4 FAQ
Budou-li nějaké, pište na adresu uvedenou zde.
Footnotes:
Nebo se mi na to zatím nepodařilo přijít… Podobně se obávám, že na rozdíl od korpusového manažeru ANNIS nelze hledat ve více vrstvách paralelně.
Zpětné lomítko jakož i další značky často používané v regulárních výrazech se na základní české klávesnici nezadávají úplně pohodlně; v EXAKTu je možné je zadat jednodušeji tak, že kliknete pravým tlačítkem do vyhledávacího boxu a vyberete kýžený znak ze seznamu, který se objeví.
Jsou stejné – doufám.